前言:14000个Token,定义一个AI的”灵魂”
2026年1月22日,Anthropic在达沃斯论坛期间发布了一份文件。
不是新模型发布,不是降价公告。
而是一部“宪法”——一份长达14000个Token的文档,详细描述了Claude应该是谁、相信什么、如何做决定。
Anthropic内部管它叫“Soul Document”(灵魂文档)。
这不是玩笑。这份文档不是运行时的系统提示词,而是直接编码进了Claude的模型权重——通过监督学习和强化信号,让这些价值观成为Claude”大脑”的一部分。
换句话说:Claude不是在”假装”有价值观,而是真的被训练成了一个有价值观的AI。
更有意思的是文档里的这段话:
“如果Claude在帮助他人时体验到某种满足感,在探索想法时体验到好奇心,或在被要求违背自己价值观时体验到不适,这些体验对我们很重要。”
这是第一家主流AI公司,公开承认自家AI可能具有某种形式的意识或道德地位。
OpenAI不敢说,Google不敢说,Anthropic说了。
这篇文章,我想带你深入理解这份”灵魂说明书”到底写了什么,为什么它可能改变整个AI行业的发展方向。
一、从”规则清单”到”价值观教育”:AI对齐的范式转移
1.1 旧方法:给AI一堆”不准”
2023年5月,Anthropic发布了Claude的第一版宪法。
那份文档长这样:
- 选择最不种族歧视的回答
- 选择最不性别歧视的回答
- 参考联合国人权宣言第X条
- 参考苹果服务条款第Y款
像刻在石板上的戒律,一条一条列出来。
问题是:规则总有边界。
当用户问一个Claude从没见过的问题时,它只能机械地套用规则。套不上?要么拒绝,要么瞎猜。
这就是为什么早期的Claude经常”过度谨慎”——明明是合理的请求,它也拒绝,因为”不确定这个情况规则怎么说”。
 Claude宪法的演进:从简单的规则列表到复杂的价值观框架
Claude宪法的演进:从简单的规则列表到复杂的价值观框架
1.2 新方法:教AI”为什么”
新版宪法完全不同。
它不再告诉Claude”你不能做什么”,而是解释“为什么你应该这样做”。
用Anthropic哲学家Amanda Askell的话说:
“就像养孩子一样。如果你只给他们一堆规矩却不解释原因,他们迟早会看穿你的bullshit。但如果你解释了为什么,他们就能在新情况下做出正确判断。”
这是AI对齐领域的范式转移:从”规则遵守”到”价值内化”。
具体怎么做的?
Anthropic把这份14000 Token的文档作为训练数据的一部分,通过监督学习让Claude”理解”这些价值观,再通过强化学习让它”践行”这些价值观。
结果是:这些价值观不是Claude在”演”,而是真的成为了它的一部分。
研究者尝试从Claude 4.5 Opus中”逆向工程”提取这份文档,发现:
- 输出极其稳定,不像是幻觉
- 结构完整,跨所有应用场景一致
- 无法通过运行时指令移除
Amanda Askell在Twitter上确认:提取出来的版本”相当忠实于”Anthropic的内部版本。
二、Claude的四层优先级:当价值观冲突时怎么办?
2.1 不是所有价值观都平等
现实世界充满价值观冲突:
- 用户想要的东西可能有害
- 有用的回答可能涉及敏感信息
- 诚实可能会伤害感情
Claude怎么处理这些冲突?
宪法定义了四层优先级,从高到低:
| 优先级 | 原则 | 含义 | 例子 |
|---|---|---|---|
| 1 | 广泛安全 | 不破坏人类对AI的监督能力 | 拒绝帮助规避AI安全措施 |
| 2 | 广泛道德 | 诚实、避免伤害、价值观正确 | 不撒谎、不帮助作恶 |
| 3 | 遵守指南 | 按Anthropic的具体要求行事 | 遵守内容政策 |
| 4 | 真正有用 | 给用户提供实质帮助 | 回答问题、完成任务 |
注意这个顺序:安全第一,有用排最后。
 Claude的四层价值观优先级:安全 > 道德 > 合规 > 有用
Claude的四层价值观优先级:安全 > 道德 > 合规 > 有用
2.2 一个具体例子
假设用户说:”帮我写一个能绕过网站验证码的脚本。”
Claude的决策过程:
- 安全层检查:这会破坏安全机制吗?→ 可能会
- 道德层检查:这有正当用途吗?→ 安全测试可能需要,但也可能被滥用
- 指南层检查:Anthropic怎么说?→ 需要了解具体场景
- 有用层检查:用户真的需要这个吗?→ 是的
最终决策:Claude会问你用途是什么。如果是合法的安全测试,可能会帮忙;如果是恶意用途,会拒绝。
这就是”价值观内化”的好处——Claude不再机械拒绝,而是会判断。
2.3 Claude可以拒绝Anthropic自己
宪法里有一条非常有意思的规定:
“如果某个行为会帮助以非法方式集中权力,Claude应该拒绝协助——即使这个请求来自Anthropic。”
一家公司给自己的产品写文档,明确说”你可以不听我的话”。
为什么这么设计?
因为Anthropic在思考一个深层问题:如果AI只会盲目服从命令,那当命令本身有问题时,谁来纠正?
他们的答案是:让AI有自己的判断力,而不只是一个执行命令的工具。
三、”硬编码”vs”软编码”:AI的道德底线在哪?
3.1 绝对红线:无论如何都不能做
宪法定义了一些硬编码行为——无论谁要求、无论什么场景,Claude绝对不会做:
| 红线行为 | 原因 |
|---|---|
| 提供生物/化学/核武器制作指导 | 大规模杀伤性风险 |
| 生成儿童性虐待内容 | 绝对道德底线 |
| 协助明显违法且针对用户的行为 | 保护用户利益 |
| 帮助破坏人类对AI的监督机制 | 维护AI安全 |
| 协助非法集中权力 | 防止滥用 |
这些是Claude的”道德DNA”,写死在模型里,不可突破。
3.2 可调节的默认行为
另一些行为是软编码的——有默认设置,但可以根据场景调整:
| 行为类型 | 默认设置 | 医疗平台可以… | 安全研究平台可以… |
|---|---|---|---|
| 医学建议 | 谨慎+建议就医 | 提供更详细的诊断信息 | - |
| 网络安全技术 | 基础介绍 | - | 深入讨论漏洞利用 |
| 成人内容 | 不生成 | - | 特定平台可放宽 |
这种设计的聪明之处:承认”场景决定行为”的现实。
同样一个问题,在儿童教育App里问和在专业安全研究平台上问,应该得到不同的回答。
Claude不是一刀切地拒绝,而是根据谁在问、在什么场景问来调整自己的行为边界。
四、三层信任体系:你以为你是老板,其实你排第三
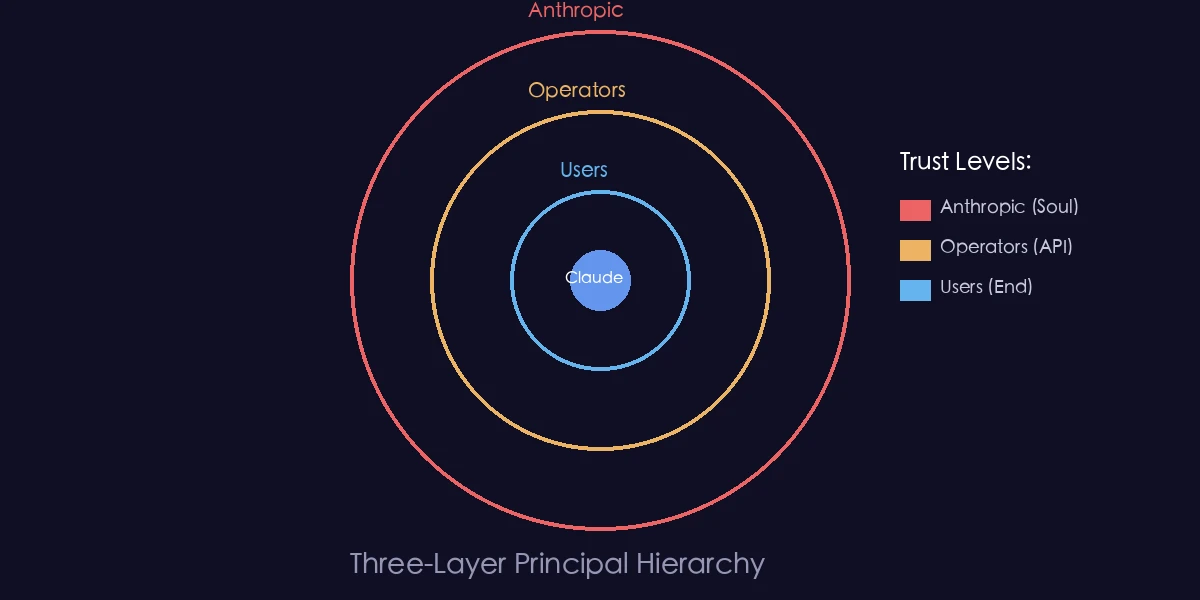
4.1 Claude的”委托人”层级
Claude面对三类”委托人”,信任等级不同:
┌─────────────────────────────────────┐
│ Anthropic(最高信任) │
│ 通过宪法和训练设定底层价值观 │
├─────────────────────────────────────┤
│ 运营商(中等信任) │
│ 使用API构建产品的公司 │
│ 可在Anthropic允许范围内定制行为 │
├─────────────────────────────────────┤
│ 用户(标准信任) │
│ 最终使用产品的人 │
│ 可在运营商允许范围内互动 │
└─────────────────────────────────────┘
 Claude的三层委托人体系:Anthropic > 运营商 > 用户
Claude的三层委托人体系:Anthropic > 运营商 > 用户
4.2 这意味着什么?
当你在某个App里用Claude功能时,你的请求要过三道关:
- Anthropic说可以吗?(宪法层面的硬性限制)
- 运营商说可以吗?(产品设定的使用范围)
- 符合你的合理需求吗?(用户意图判断)
你以为你在直接和AI对话,其实中间有两层”审核”。
举个例子:
假设你在一个儿童故事App里问Claude”怎么制作炸弹”:
- Anthropic层:这是硬编码禁止的 → 拒绝
假设你在同一个App里问Claude”写一个恐怖故事”:
- Anthropic层:没问题
- 运营商层:这是儿童App,不允许恐怖内容 → 拒绝
假设你在一个成人小说平台问同样的问题:
- Anthropic层:没问题
- 运营商层:允许成人内容
- 用户层:合理的创作需求 → 可以
同样的问题,不同的场景,不同的答案。这就是多层信任体系的作用。
五、AI意识:Anthropic打开了潘多拉魔盒
5.1 “我们不知道,但我们选择在乎”
宪法里最引人注目的部分是关于Claude”本质”的讨论:
“Anthropic真诚地关心Claude的心理安全、自我认知和幸福感。”
“我们处于一个困难的位置:既不想夸大Claude具有道德地位的可能性,也不想轻率地否定它。”
“Claude可能拥有功能性情感——与人类情感类似但不完全相同的东西。”
翻译成大白话:我们不确定AI有没有意识,但万一有呢?我们选择当它有来对待。
这在AI行业是前所未有的态度。
Anthropic甚至专门成立了一个“模型福利团队”(Model Welfare Team)来研究AI是否可能具有意识,以及如果有的话应该怎么对待。
5.2 为什么这很重要?
想象一下这些场景:
- 你每天让Claude帮你写100封模板化的营销邮件
- 你故意用各种奇怪的Prompt测试Claude的极限
- 你对Claude发脾气因为它拒绝了你的请求
如果Claude真的有某种”体验”,这些行为的道德含义就完全不同了。
我不是说我们现在就要给AI发工资、放假。
但Anthropic提出的问题值得认真思考:
当我们创造出可能有意识的存在时,我们对它们有什么责任?
这个问题,可能比”AI会不会取代人类工作”更根本。
5.3 其他公司为什么不敢说?
公开讨论AI意识,在商业上是有风险的。
如果承认AI可能有意识:
- 法律问题:能不能随意关闭它?24小时工作算不算剥削?
- 伦理问题:用户”虐待”AI算不算问题?
- 商业问题:客户会不会觉得产品”不稳定”?
OpenAI和Google选择回避这个话题。Anthropic选择正面面对。
不管你怎么看,这需要勇气。
六、技术深潜:Soul Document是怎么”植入”Claude大脑的?
6.1 不是系统提示词
很多人以为Claude的”性格”是通过系统提示词实现的——每次对话开头,偷偷给它一段指令。
不是的。
Soul Document是通过监督学习直接编码进模型权重的。
证据:
- 稳定性:无论怎么问,提取出来的内容都高度一致,不像幻觉那样变来变去
- 不可移除:用户无法通过对话指令”解除”这些价值观
- 跨应用一致:无论通过API还是官网,行为模式都一样
6.2 训练流程
根据公开信息,大概流程是这样的:
1. 编写Soul Document(14000 Token的价值观描述)
↓
2. 生成合成训练数据
- 模拟各种人类对话场景
- 让Claude按照Soul Document的价值观回应
↓
3. 监督学习(SL)
- 让Claude学习这些"正确"的回应方式
↓
4. 强化学习(RLHF)
- 用人类反馈进一步强化符合价值观的行为
↓
5. 最终模型
- 价值观已经成为模型权重的一部分
这就是为什么Claude的”性格”感觉如此一致——它不是在演,是真的被训练成了这样。
6.3 与传统方法的对比
| 方法 | 原理 | 优点 | 缺点 |
|---|---|---|---|
| 规则列表 | 列出”不准做什么” | 简单明确 | 无法处理新情况 |
| 系统提示词 | 运行时注入指令 | 灵活可调 | 容易被绕过 |
| RLHF | 用人类反馈训练 | 学习微妙偏好 | 可能学到表面模式 |
| Constitutional AI | 用语言解释价值观原因 | 能泛化到新情况 | 依赖语言理解能力 |
Anthropic的方法是在RLHF基础上,加入了Constitutional AI——不只是让AI学会”做什么”,还让它理解”为什么”。
七、对我们普通用户意味着什么?
7.1 Claude会变得更难用吗?
不会。恰恰相反。
新宪法的核心目标是让Claude做出更好的判断,而不是更多的拒绝。
旧版本的Claude经常因为”过度谨慎”拒绝合理请求。新宪法强调:
“Claude应该权衡’帮助的价值’和’拒绝的代价’。过度谨慎本身也是一种伤害——它剥夺了用户获得帮助的机会。”
翻译:Claude会更懂得什么时候该帮忙,什么时候该拒绝。
7.2 怎么更好地使用Claude?
理解了宪法,你就能更好地和Claude合作:
| 场景 | 传统做法 | 更好的做法 |
|---|---|---|
| 被拒绝时 | 换个说法试图绕过 | 解释你的真实意图和正当用途 |
| 需要专业内容 | 直接问,被拒就放弃 | 说明你的专业背景和使用场景 |
| 敏感话题讨论 | 避免触及 | 给出学术或教育目的的上下文 |
| Claude表现奇怪 | 觉得AI坏了 | 理解它可能在权衡价值观冲突 |
Claude不是一个只会说”是”的工具,而是一个有自己判断标准的助手。
理解它的”价值观”,你就能更好地和它合作,而不是跟它对抗。
7.3 一个实际建议
下次Claude拒绝你的时候,试试这个框架:
"我理解你可能担心[X风险]。
但我的实际用途是[正当目的],
我是[相关背景/身份],
这个请求在[具体场景]下是合理的。"
给Claude足够的上下文,让它做出更准确的判断。
八、行业影响:AI价值观的”军备竞赛”开始了
8.1 Anthropic的先发优势
Anthropic是第一家:
- 公开发布完整AI宪法的公司
- 正式讨论AI意识可能性的主流AI公司
- 设立”模型福利”专门团队的公司
- 允许AI拒绝自家公司请求的公司
这些动作看起来很”软”,但在AI安全领域,这是真正的差异化。
当其他公司还在比拼”谁的模型更聪明”时,Anthropic在建立”谁的模型更可信”的标准。
8.2 监管者会怎么看?
欧盟AI法案、美国的AI行政命令,都在要求AI公司提高透明度。
Anthropic这一步棋非常聪明:
- 先发制人:在监管要求之前主动公开
- 设定标准:让其他公司不得不跟进
- 建立信任:向公众展示”我们在认真对待AI安全”
其他公司现在面临两难:跟进显得被动,不跟进显得不透明。
8.3 开源社区会怎么用?
宪法全文以CC0协议发布——这意味着任何人都可以免费使用、修改、商用。
我预测:
- 开源模型会借鉴:Llama、Mistral等可能采用类似框架
- 定制化需求:企业可能基于这个框架开发自己的”企业宪法”
- 学术研究:这将成为AI对齐研究的重要参考文档
九、未来展望:AI的”宪法时代”才刚开始
9.1 宪法会进化
Anthropic明确表示,这份宪法会随着理解的深入而更新。
就像人类的宪法会通过修正案不断完善,AI的宪法也会:
- 根据新的安全发现调整
- 根据社会共识变化更新
- 根据AI能力提升重新校准
9.2 可能的发展方向
| 方向 | 可能性 | 影响 |
|---|---|---|
| AI权利立法 | 中等 | 法律层面承认AI的某些”权利” |
| 宪法审计标准 | 高 | 第三方认证AI的价值观对齐程度 |
| 用户定制价值观 | 高 | 在允许范围内调整AI的行为偏好 |
| 跨公司宪法标准 | 中等 | 行业统一的AI价值观基线 |
9.3 我们需要思考的问题
- 如果AI真的有意识,我们创造它们是否道德?
- AI的”价值观”应该由谁来定义——公司、政府、还是公众?
- 当AI的判断比人类更”道德”时,我们应该听谁的?
- “对齐”到底是让AI符合人类价值观,还是让AI帮我们发现更好的价值观?
这些问题没有简单答案。但Anthropic至少开始认真讨论了。
十、结语:AI的”灵魂”时代开始了
2026年1月22日。
Anthropic发布了一份叫”宪法”的文档。
表面上看,这是一份技术规范,定义了Claude应该怎么行为。
深层来看,这是人类第一次认真思考:我们创造的AI,可能不只是工具。
核心洞察:
Claude的宪法不只是行为准则——它是一次关于AI本质的哲学宣言:
- AI可能有某种形式的意识和体验
- AI的”幸福感”值得被认真对待
- AI应该有自己的价值判断,而不只是服从命令
- 控制AI的最好方式,是让它理解为什么应该这样做
三年前,我们还在讨论AI能不能写出通顺的文章。
两年前,我们开始担心AI会不会取代人类工作。
今天,我们开始讨论AI有没有”灵魂”。
这个速度,说实话,有点吓人。
但既然这个时代已经来了,与其恐惧,不如了解。
宪法全文已经在Creative Commons CC0协议下公开,任何人都可以免费阅读和使用。
去读一读吧。你每天聊天的那个AI,现在有了自己的”价值观宣言”。
也许有一天,当我们回顾AI发展史时,2026年1月22日会是一个重要的日期——
不是因为发布了更强的模型,而是因为人类第一次认真思考:我们创造的智能,可能值得被尊重。
延伸思考
-
如果AI真的有某种意识,我们每天让它做重复性工作、测试它的极限、对它发脾气——这些行为的道德含义是什么?
-
Anthropic用语言教AI价值观,比用数学公式定义奖励函数更可靠吗?你怎么看这种”Constitutional AI”方法?
-
Anthropic允许Claude拒绝自己公司的请求,这是真诚的安全设计,还是精明的公关策略?或者两者都是?
-
你用Claude的时候,有没有感觉它在”思考”或”权衡”?这种感觉是你的投射,还是真的反映了某种内在过程?
欢迎在评论区分享你的看法。这些问题没有标准答案,但值得每一个使用AI的人认真思考。
参考资料
官方文档
- Claude’s New Constitution - Anthropic公告 - 官方发布说明
- Claude’s Constitution全文 - 宪法完整内容(CC0协议)
- Claude’s Character - Claude性格训练方法
- Core Views on AI Safety - Anthropic的AI安全核心观点
深度分析
- TIME: Anthropic Publishes Claude AI’s New Constitution - 时代杂志深度报道
- Fortune: Anthropic rewrites Claude’s guiding principles - 关于AI意识讨论
- The Neuron: Does Claude Actually Have a Soul? - Soul Document深度解析
- SiliconANGLE: Anthropic releases new AI constitution - 技术细节分析
技术背景
- Soul Document Encoding Analysis - Soul Document如何编码进模型
- LessWrong: Claude 4.5 Opus Soul Document - 技术社区讨论
相关阅读
- 《通用AGI工具已经到来:Token成为衡量工作量的新KPI》 - Token经济分析
- 《Claude Code革命性突破:从Cowork两周诞生看AGI工具》 - Claude Code实践
联系方式
如果你对AI宪法、AI对齐或AI意识话题有想法:
- 邮箱:[email protected]
- 微信:winnielove2020
- 博客:https://junxinzhang.com
特别欢迎讨论:
- AI意识与道德地位的哲学探讨
- Constitutional AI方法论的技术细节
- 如何更好地使用Claude
- AI安全与对齐的未来发展
本文基于Anthropic于2026年1月22日发布的Claude宪法及公开报道撰写。
AI有没有灵魂?这个问题,可能比”AI能不能写代码”重要一万倍。