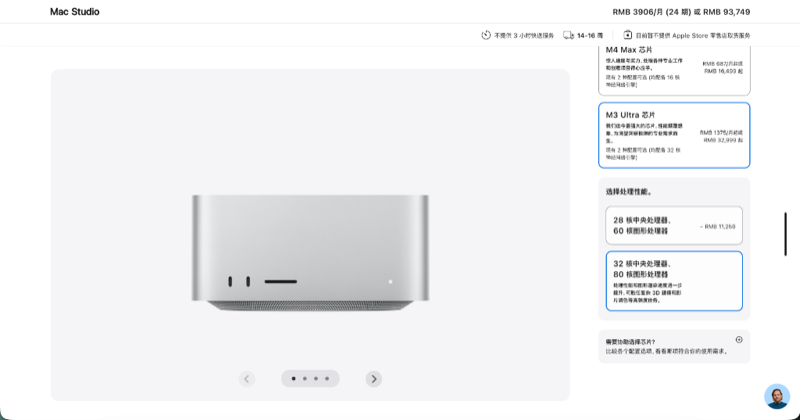
云端 AI 订阅全面崩盘的那一周,我在苹果官网下了个 Mac Studio M3 Ultra 的单。发货日期:14-16 周。
上海这边的情况更直观:直接去 Apple Store 自提有货,但只有标准版配置。想要 M3 Ultra 高配?对不起,线上下单,等 14 到 16 周。
不是我一个人在抢。Reddit、Hacker News、国内技术社区,到处都在讨论同一件事——Mac Studio 快断货了。
苹果没打过 AI 算力的主意。但当 Token 成为生产力、数据安全成为底线,Mac Studio 无心插柳,成了最合理的选择。

一、云端靠不住了,然后呢?
两天前我写了《AI 订阅全面崩了》——Claude Max 一条提示词额度清零,Antigravity Pro 配额暴降 97%,250 万人从 ChatGPT 逃到 Claude 发现 GPU 照样不够。
充钱不是大爷,GPU 才是。 但问题来了:
| 痛点 | 现状 |
|---|---|
| 限流 | Claude 高峰期额度加速消耗,倍率不公开 |
| 封号 | Anthropic 半年封禁 145 万账号,申诉通过率 3.3% |
| 数据泄露 | 你的代码、文档、商业机密全在别人服务器上 |
| 涨价 | 从 $20 到 $200,下一步可能按量计费 |
如果你是个人开发者,忍忍也就过去了。但如果你是企业——你的核心代码跑在别人的 GPU 上,你的商业文档被用来训练别人的模型,你的账号随时可能被封。 这不是成本问题,是生存问题。
当云端 AI 的三大风险——限流、数据泄露、平台依赖——同时爆发,本地算力不再是「备选方案」,而是「必选项」。
二、为什么是 Mac Studio?
市面上能跑大模型的本地设备不少——高端游戏显卡、英伟达工作站、自建服务器。但 Mac Studio 在 AI 本地部署上有一个别人做不到的优势:统一内存。
| 设备 | GPU 显存 | 能跑的模型规模 | 功耗 | 噪音 |
|---|---|---|---|---|
| RTX 4090 | 24GB | 70 亿参数(勉强) | 450W | 风扇轰鸣 |
| 双卡 4090 | 48GB | 130 亿参数 | 900W | 需要专业散热 |
| Mac Studio M3 Ultra | 256GB 统一内存 | 千亿参数 | 140W | 几乎静音 |
关键在于——大模型推理的瓶颈不是算力,是内存。一个 700 亿参数的模型,FP16 精度需要 140GB 显存。英伟达方案要 6 张 4090 才够,功耗接近 3000W,还需要 NVLink 桥接。Mac Studio?一台机器,256GB 统一内存,140W 功耗,放在桌上没声音。
苹果官网明确写着:「With up to half a terabyte of unified memory, you can run LLMs entirely in memory.」 苹果自己可能都没想到,这句话会成为 Mac Studio 最强的卖点。
统一内存架构让 Mac Studio 做到了英伟达方案做不到的事:用一台桌面设备,安静地跑千亿参数大模型。这不是性能优势——是形态优势。

三、谁在买?买来干什么?
Mac Studio 的新买家画像已经变了。不只是视频剪辑师和音乐制作人——AI 工程师、创业团队、对数据安全有刚需的企业,正在成为主力。
| 场景 | 具体用法 | 为什么必须本地 |
|---|---|---|
| 代码生成 | 本地跑 Code Llama / DeepSeek-Coder | 核心代码不能上传云端 |
| 文档分析 | 本地跑 Qwen-72B 处理合同、财报 | 商业机密零泄露 |
| AI 产品开发 | 本地推理 + API 混合架构 | 降低 Token 成本 70% |
| 医疗/金融 | 本地部署合规模型 | 监管要求数据不出境 |
我自己的 Token 年投入是 8 万人民币。如果把高频推理任务迁移到本地 Mac Studio,保守估计能省 40-50%。更重要的是——本地推理没有额度限制,没有高峰限流,没有封号风险。
社区公开测试数据显示,用 MLX 框架在 Mac Studio M3 Ultra 上跑 DeepSeek-R1 70B(4-bit 量化),推理速度约 10-20 token/s。不算快,但稳定、安全、7×24 无限使用。
Mac Studio 不是最快的 AI 推理设备,但它可能是唯一一台你能放在办公桌上的、安静的、数据完全可控的千亿参数大模型工作站。

四、我在等 M5 Ultra 512G
现在的 M3 Ultra 顶配是 256GB 统一内存。够跑 700 亿参数的模型(FP16),量化后能上千亿。但我想要的是——512GB。
按苹果芯片迭代节奏:
| 芯片 | 统一内存上限 | 内存带宽 | 预计发布 |
|---|---|---|---|
| M3 Ultra | 256GB | 819 GB/s | 已发布 |
| M4 Ultra | 256-384GB | ~1000 GB/s | 2026 Q4(预测) |
| M5 Ultra | 512GB | ~1200 GB/s | 2027(预测) |
512GB 统一内存意味着什么?FP16 精度下直接跑 4050 亿参数的模型。 不需要量化,不需要妥协。本地跑一个完整的 GPT-4 级别模型,不是幻想——是两代芯片之后的现实。
我现在的策略很清楚:核心生产用 API 按量计费,高频推理等 M5 Ultra 512G 一步到位。 当别人还在为云端限流焦虑的时候,把算力握在自己手里。
M5 Ultra 512GB 不只是一台电脑——它是一个人的 AI 算力中心。当 Token 成为生产力的度量衡,拥有自己的算力,就是拥有自己的未来。

写在最后
苹果做 Mac Studio 的初衷是给视频剪辑师和音乐人用的。统一内存架构是为了让 Final Cut Pro 和 Logic Pro 更流畅。没人想到,这个设计会在 AI 时代成为杀手级特性。
无心插柳柳成荫。苹果没有做 AI 芯片的野心,但它做出了最适合跑 AI 的消费级硬件。
我一个人打造的 Zaokit AI 正在内测,前 1000 名用户赠送价值 150 RMB 的 Pro 计划,助力大家高效完成图文创作和 PPT 生成,唯一网站:zaokit.app。
Token 是生产力,算力是基础设施,数据安全是底线。当这三条线交汇在一起,Mac Studio 就是答案。我在等 M5 Ultra 512G——不是因为信仰,是因为数学。
相关阅读
AI 算力与订阅系列