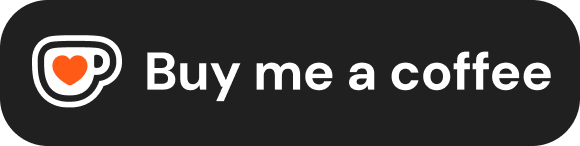前言:这不是“又一个小开关”,而是发布通道的代际变化
今天是 2026 年 2 月 14 日。过去几个月,我在自己的站点上持续做了 AI 入口改造:llms.txt、llms-full.txt、for-agents 页面、结构化摘要,以及面向 Agent 的验证脚本。
Cloudflare 在 2026 年 2 月 12 日发布了 Markdown for Agents。很多人把它理解成“把 HTML 转成 Markdown 的便利功能”。
我的结论更激进一点:它是个人站从“只服务人类读者”,升级为“同时服务人类读者 + AI Agent”的关键基础设施。

一、为什么这件事对个人站是“刚需”,不是“可选项”
过去做内容分发,我们默认“入口只有人”。
现在不同了。越来越多流量先经过 AI 搜索、答案引擎、站内 Agent,再决定要不要把用户导向你的原文页面。也就是说,你的第一读者,很多时候已经不是人,而是模型。
Cloudflare 官方给了一个非常直观的数据:同样内容,HTML 输入大约 16,180 tokens,Markdown 约 3,150 tokens,减少接近 80%。
这不是数字游戏,而是三个直接结果:
- 模型读取更快,摘要与引用延迟更低。
- 解析噪音更少,答案稳定性更高。
- 推理成本下降后,你的内容被“完整读完”的概率会更大。
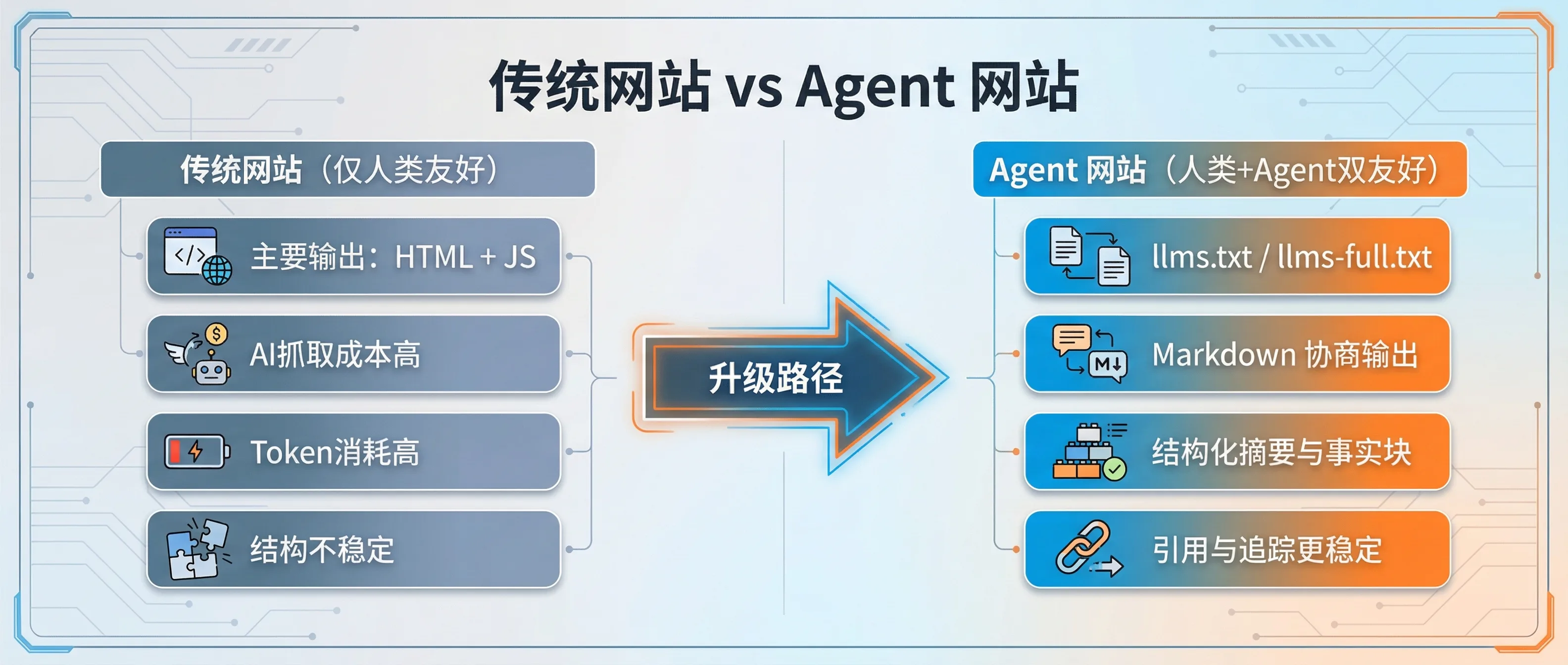
二、Cloudflare 到底开放了什么?先把能力边界讲清楚
如果只记一句话:Cloudflare 给了你一个“边缘层翻译器”。
你可以通过两种方式拿到 Markdown:
- 请求
https://your-domain.com/cdn-cgi/llm - 对原 URL 发
Accept: text/markdown进行内容协商
除此之外,还有两个很关键但容易被忽略的点:
- 内容信号策略(Content Signals)可以细化 AI 爬虫行为,并附加信号头。
- 转换条件有明确限制:
text/html、Content-Length <= 1MB、源站不要直接给压缩 HTML,否则可能回退原始 HTML。
这意味着:它不是“万能魔法”。你仍然要做好源站结构、页面体积、内容组织和缓存策略。
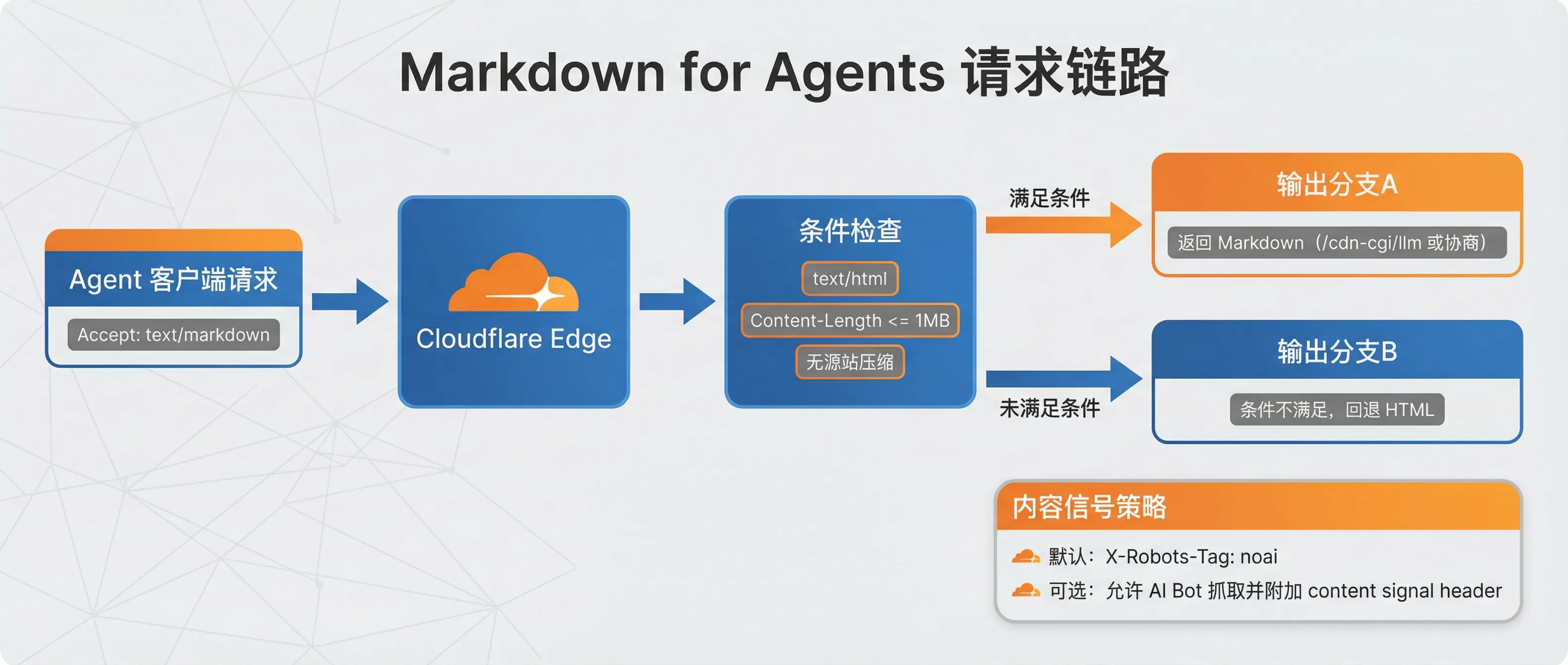
三、作为 Cloudflare 深度用户,我给个人站的升级建议是“四层栈”
我参考了自己最近几篇文章的实操路径(例如 《AI Agent Skill 与 MCP 新手指南》、《独立开发者AI军备竞赛实录》、《Gemini-3 Deep Think 实测》),总结出一套更稳的升级框架:
第 1 层:内容层(Content)
每篇文章至少提供:
- 可复述的一句话摘要
- 关键事实块(可被直接引用)
- FAQ(覆盖高频追问)
第 2 层:协议层(Protocol)
保证这些入口长期稳定:
llms.txtllms-full.txtsitemap.xmlfeed.xml
第 3 层:边缘层(Edge)
在 Cloudflare 侧启用与治理:
- Markdown for Agents
- Content Signals Policy
- 针对 AI Bot 的抓取策略与权限边界
第 4 层:观测层(Observability)
别只看 PV,要看 Agent 指标:
- Markdown 命中率
- token 成本变化
- 被引用率(被答案引擎引用的频次)
- 引用后回流转化(点击/订阅/咨询)
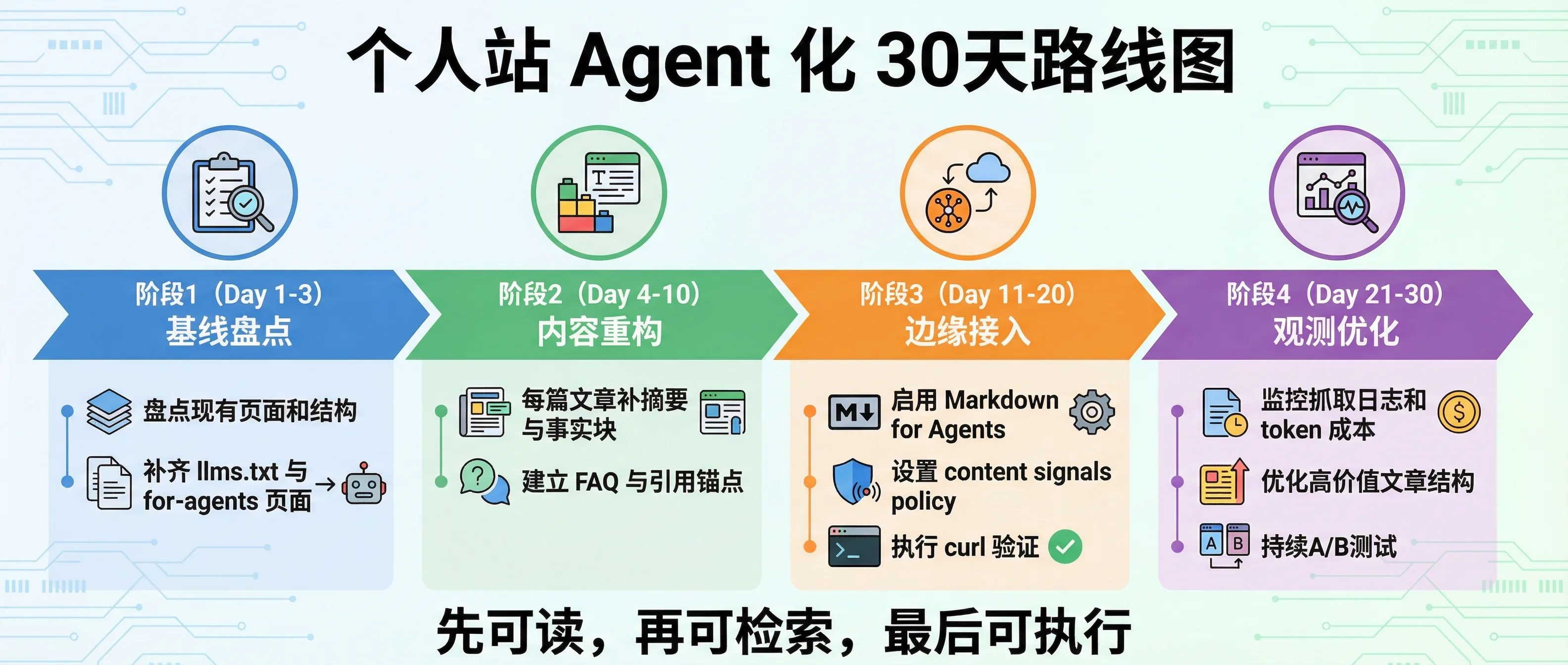
四、给普通创作者也能执行的 30 天落地计划
很多人觉得“Agent 优化”很难,是因为一上来就做平台级改造。
我的建议是:先做低成本、可复用、可验证的动作。
- Day 1-3:盘点现有内容与入口,补齐
for-agents页面 - Day 4-10:给高价值文章补摘要、事实块、FAQ
- Day 11-20:启用 Cloudflare Markdown for Agents,执行
curl验证 - Day 21-30:观测抓取与引用数据,集中优化高潜文章
五、几个容易踩的坑:越早知道,越省时间
1) 把“AI 搜索”与“AI 训练”混为一谈
检索曝光和训练授权是两件不同的事。建议用策略分层,不要一次性全开或全关。
2) 只做边缘转换,不做内容结构
Markdown for Agents 可以降低噪音,但不会替你写出“可引用结构”。源内容杂乱,输出照样杂乱。
3) 把 llms.txt 当成过时方案
恰恰相反。边缘转换是“动态通道”,llms.txt 是“稳定目录”。两者叠加才是长期方案。
4) 只看访问量,不看“被机器理解后的传播能力”
Agent 时代,真正的竞争指标是:你是否被正确理解、准确引用、持续复用。
六、最小验证清单(可以直接抄)
# 默认请求(通常是 HTML)
curl -I https://junxinzhang.com/
# 请求 markdown 协商输出
curl -I https://junxinzhang.com/ -H 'Accept: text/markdown'
# 看 body 前 40 行是否仍是完整 HTML 标签
curl -s https://junxinzhang.com/ -H 'Accept: text/markdown' | head -n 40
如果你在 Cloudflare 上托管站点,建议把这套检查做成日常巡检脚本。我的站点已经有 scripts/verify-markdown-for-agents.sh,可以直接跑。
结语:面向 Agent 不是“迎合机器”,而是扩大你的真实受众
我把这轮升级理解为一次“协议升级”:
- 对人,继续保留高质量阅读体验。
- 对 Agent,提供低噪音、可验证、可引用的内容通道。
当 Cloudflare 把这条边缘通道打开后,个人站最该做的不是观望,而是尽快把内容从“可读”推进到“可执行”。
未来的内容竞争,不只是写得好,而是谁先成为 Agent 生态里“可被稳定调用的节点”。
参考资料(官方)
- Cloudflare Blog: Introducing markdown for agents
- Cloudflare Docs: Markdown for Agents
- Cloudflare Docs: Content Signals Policy
- Cloudflare Blog: Control how AI crawlers and bots access your content