前言:一个”会暂停思考”的AI
2026年2月13日。
2026年2月12日,Google DeepMind正式发布了Gemini-3 Deep Think——一个”会暂停思考”的AI推理模式。
作为Google AI Ultra的订阅用户($249.99/月,没错,又新开通了一个烧钱的订阅<-_->),我第一时间拿到了Deep Think的访问权限,花了一整天时间深度测试。
今天这篇文章,不是技术评测报告,是一个重度AI用户的真实体感。

先说结论:Deep Think不是"更快的AI",而是"更慢但更对的AI"。这个区别比你想象的重要得多。
一、什么是Deep Think?为什么它值得单独写一篇文章?
1.1 一句话解释
普通AI模型的工作方式:你提问 → 它立刻开始输出答案。像一个反应很快但有时候不过脑子的同事。
Deep Think的工作方式:你提问 → 它暂停 → 在脑子里生成多个假设 → 逐一评估 → 精炼最优方案 → 然后才开始回答。 像一个收到问题后会说”让我想想”的资深专家。
Google把这种技术叫做“并行思考”(Parallel Thinking)——模型在回答前同时生成多个思路,评估哪个最靠谱,再把最好的那个交给你。
这不是噱头。它在基准测试上的表现说明了一切:
| 基准测试 | Gemini 3 Deep Think | Claude Opus 4.6 Thinking Max | GPT-5.2 Thinking xhigh |
|---|---|---|---|
| ARC-AGI-2(抽象推理) | 84.6% | 68.8% | 52.9% |
| Humanity’s Last Exam | 48.4% | 40.0% | 34.5% |
| GPQA Diamond(研究生级科学) | 93.8% | ~88% | 93.2% |
| Codeforces Elo | 3455 | 2352 | — |
| IMO 2025(数学奥赛) | 81.5%(金牌级) | — | 71.4% |
| IPhO 2025(物理奥赛理论) | 87.7% | 71.6% | 70.5% |
| IChO 2025(化学奥赛理论) | 82.8% | — | 72.0% |
数据来源:Google DeepMind
注意看ARC-AGI-2这一行——这是测试”真正的推理能力”的基准,不是背答案,而是面对全新的、从没见过的抽象问题能不能推理出答案。
Deep Think拿了84.6%,Claude Opus 68.8%,GPT-5.2只有52.9%。
差距不是一点半点,是断层式的领先。
1.2 为什么我说这值得单独写一篇文章
因为在我过去一个月的AI军备竞赛中,我已经用了11个Claude MAX账号和2个Google AI Ultra账号。我不是看新闻的人,我是每天把这些模型用到触发限额的人。
从这个视角出发,Deep Think带来的变化是真实可感的。
二、真实使用场景:逐一拆解体感
我用Deep Think跑了五个真实场景。不是”帮我写首诗”这种玩具级测试,而是我日常工作中真正会遇到的问题。
2.1 场景一:复杂数学推理
测试任务: 一道涉及组合优化的量化交易策略数学建模问题。
体感:
Deep Think在收到问题后,沉默了大约45秒。屏幕上能看到它的”思考过程”——它列出了3个不同的建模方向,逐一分析了每个方向的复杂度和适用条件,最后选择了一个混合方法。
对比Claude Opus: Opus的回答来得更快(约10秒),思路也清晰,但它直接给了一个方案,没有对比其他可能性。Deep Think的回答更像是一个研究员的分析报告,Opus的回答更像是一个高级工程师的快速方案。
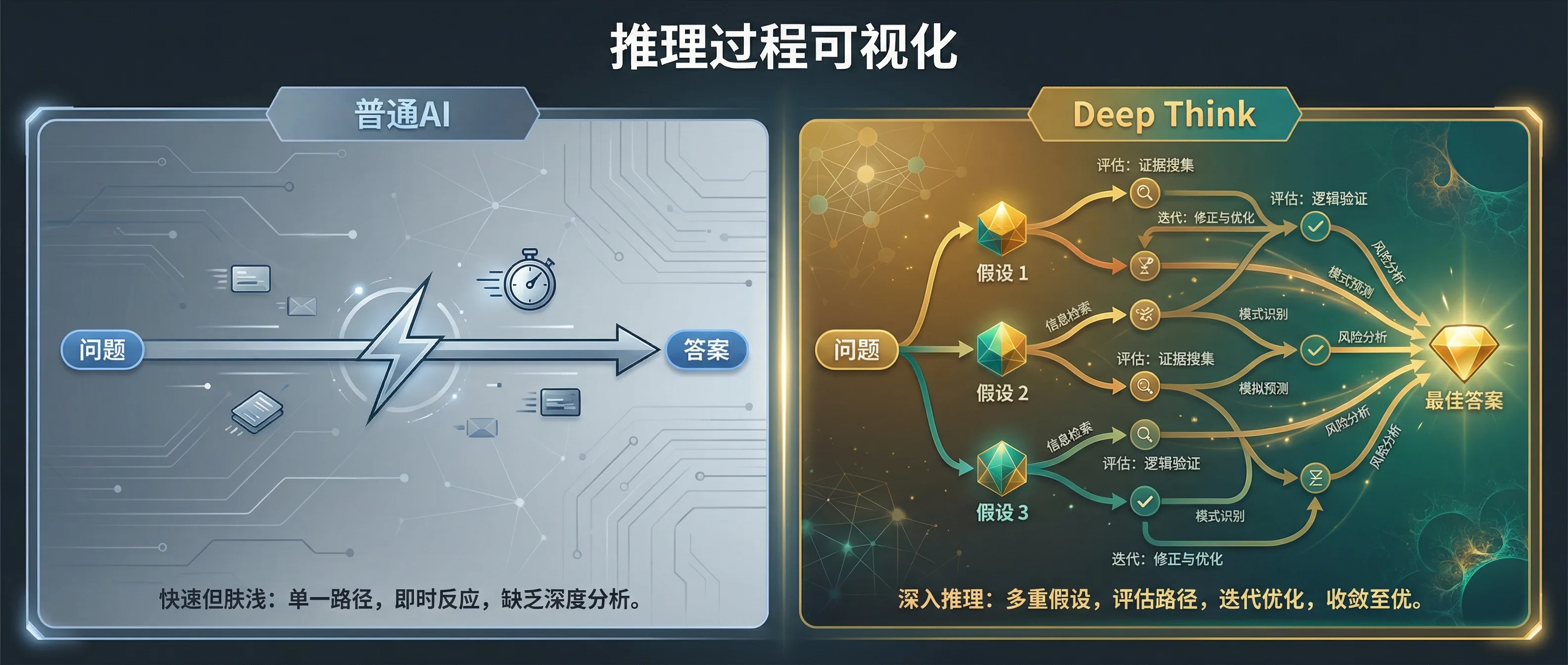 Deep Think的推理过程可视化:先发散多个假设,再收敛到最优方案
Deep Think的推理过程可视化:先发散多个假设,再收敛到最优方案
体感评分:Deep Think 9/10 vs Claude Opus 7.5/10 Deep Think在这类需要”探索问题空间”的任务上,优势非常明显。
2.2 场景二:代码生成与调试
测试任务: 用Python实现一个多因子量化选股策略,包括因子计算、回测框架和风险控制模块。
体感:
这里出现了一个有趣的现象——Deep Think的代码质量更高,但经常写到一半”思考过多”,输出被截断。
这是Deep Think目前最大的痛点:输出上下文只有64,000 Token(具体可输出字数取决于语言和格式),而Gemini 2.5 Deep Think有192,000 Token。模型花了太多Token在内部推理上,留给实际输出的空间就不够了。
相比之下,Claude Opus在代码生成上的体验更流畅——它不会”想太多”,而是直接、高效地产出可用代码。SWE-bench Verified的成绩也证明了这一点:Claude Opus 80.9% vs Gemini 3 Pro 76.2%。
体感评分:Deep Think 7/10 vs Claude Opus 9/10 代码生成场景,Claude Opus依然是王者。Deep Think的思考深度反而成了负担。
2.3 场景三:科学文献分析
测试任务: 给Deep Think一篇关于蛋白质折叠的最新Nature论文(PDF),让它指出论文中的潜在逻辑漏洞。
体感:
这是Deep Think最让我震撼的场景。
它不仅准确理解了论文的核心论点和方法论,还指出了两个实验设计中的潜在混淆变量,以及统计分析中一个容易被忽略的多重比较问题。
Claude Opus的分析也很专业,但更偏向”总结和解释”,而非”质疑和挑战”。Deep Think的分析方式更像一个同行评审者——它会主动寻找漏洞。
根据Google DeepMind的官方介绍,他们专门开发了一个名为“Aletheia”的数学研究Agent,基于Deep Think的推理能力进行自主数学研究。
体感评分:Deep Think 9.5/10 vs Claude Opus 8/10 科学推理是Deep Think的主场。如果你是研究人员,这个功能值回票价。
2.4 场景四:创意写作与内容生成
测试任务: 为一篇技术博客生成一个引人入胜的开头,要求既有技术深度又有情感共鸣。
体感:
出乎意料地,Deep Think在这个场景下反而不如普通的Gemini 3 Pro。
它的”深度思考”机制让输出变得过于分析化——像在写论文而不是博客。而且等待时间明显更长(约30秒),对于需要快速迭代内容的场景,这个延迟很影响工作流。
Claude Opus在这里的表现最好——既有技术深度,又有叙事节奏,输出也快。GPT-5.2的创意写作能力也一直是它的强项。
体感评分:Deep Think 6/10 vs Claude Opus 8.5/10 vs GPT-5.2 8/10 Deep Think不适合创意写作。它是”推理型”选手,不是”创意型”选手。
2.5 场景五:多步骤复杂任务规划
测试任务: 规划一个从零开始的SaaS产品技术方案,包括架构设计、技术选型、开发排期和风险评估。
体感:
Deep Think在这里展现了“系统性思考”的优势——它的回答像一份完整的技术咨询报告,从多个维度交叉验证了每个决策的合理性。
 五个真实场景的体感对比:Deep Think在推理和科学分析上遥遥领先
五个真实场景的体感对比:Deep Think在推理和科学分析上遥遥领先
但这里有一个微妙的问题:Deep Think倾向于给出”学术上最优”的方案,而不是”实际最可行”的方案。 它会推荐微服务+Kubernetes+事件驱动架构,而Claude Opus会根据”你是一个独立开发者”这个上下文,推荐更务实的单体应用+渐进式拆分策略。
体感评分:Deep Think 8/10 vs Claude Opus 8.5/10 Deep Think方案更全面,但Claude Opus更懂”人”。
三、Deep Think的核心优势和致命短板
3.1 三大核心优势
优势一:推理深度无人能及
在需要”深度思考”的场景——数学推理、科学分析、逻辑验证——Deep Think的表现是断层式的领先。ARC-AGI-2的84.6%不是刷出来的,是实打实的推理能力。
优势二:多模态理解的天花板
Deep Think继承了Gemini 3的多模态基因:文本、图像、视频、音频、代码——它能同时理解所有这些格式的输入,而且有100万Token的输入上下文窗口。
你可以扔给它一段30分钟的技术演讲视频、配套的幻灯片PDF、和三篇相关论文,让它做综合分析。这种跨模态的综合推理能力,目前只有Gemini能做到。
优势三:工具集成的自然度
Deep Think能自动调用Google搜索和代码执行工具,而且调用方式非常自然——它不是”我来帮你搜一下”,而是在推理过程中无缝地引用实时信息和运行代码验证假设。
3.2 三个致命短板
短板一:输出Token的大幅缩减
从192,000 Token缩到64,000 Token,这不是小幅调整,是砍了三分之二。 对于需要长篇输出的任务(完整代码、长文章、详细报告),这是一个硬伤。
模型花了大量Token在内部推理上,留给用户的实际输出空间就捉襟见肘了。你经常会遇到回答写到一半突然停了的情况。
短板二:Google生态的碎片化
这是一个让人抓狂的问题。Deep Think在Gemini App里的表现和在Google Workspace里的表现完全是两个水平。 Workspace里的模型明显被”阉割”过,而且不同产品之间的上下文不互通。
相比之下,Claude的体验要一致得多——claude.ai、Claude Code、API,用的是同一个模型,体验是连贯的。
短板三:没有持久化工作空间
不同于Claude可以通过Project功能维护一个持久化的上下文,Gemini目前还没有一个好用的”项目空间”概念。每次对话都是从零开始,没有记忆延续。
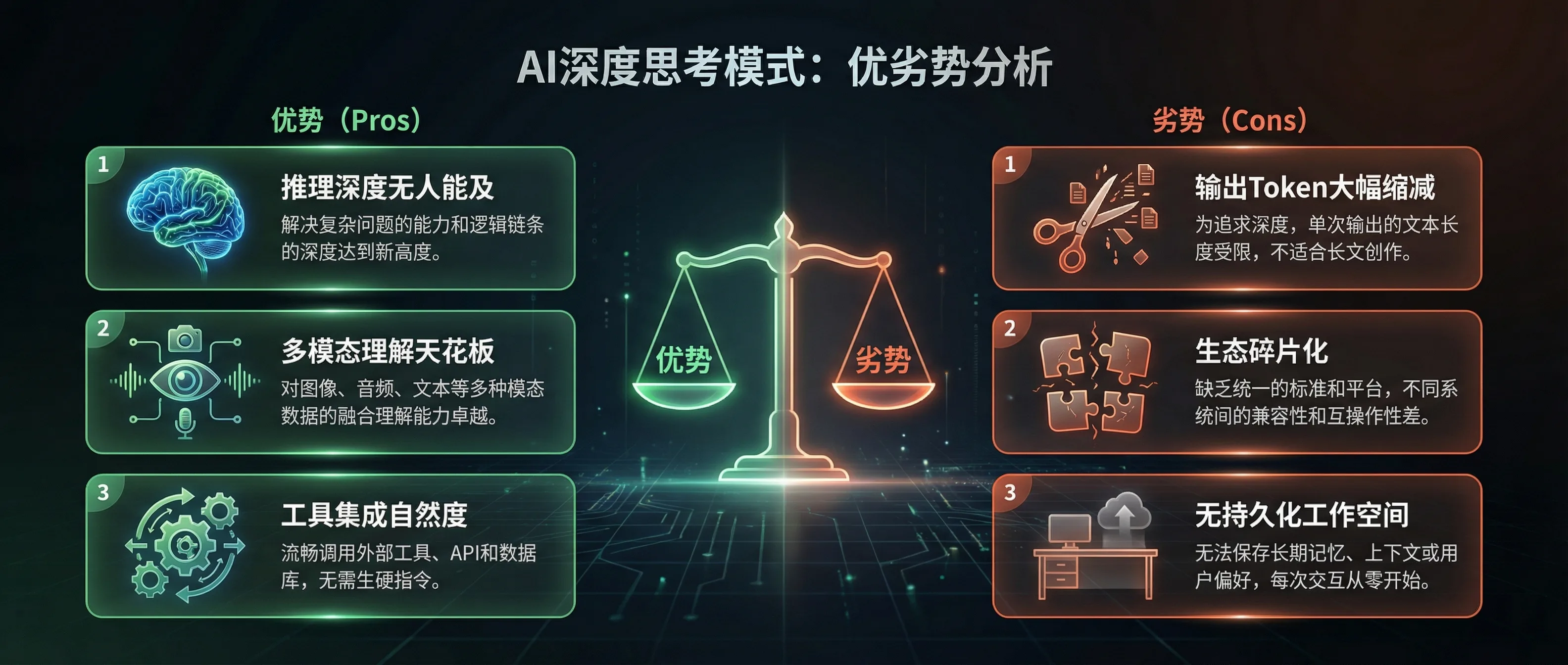 Deep Think的优势和短板一目了然:推理之王,但生态是软肋
Deep Think的优势和短板一目了然:推理之王,但生态是软肋
四、$249.99/月值不值?一个付费用户的冷静分析
4.1 谁应该订阅Google AI Ultra?
| 用户类型 | 是否推荐Ultra | 理由 |
|---|---|---|
| 科研人员/数学家 | 强烈推荐 | Deep Think在科学推理上的优势是不可替代的 |
| 独立开发者/程序员 | 不推荐 | Claude Code + Opus在编码场景更强 |
| 内容创作者 | 不推荐 | 普通Gemini 3 Pro或Claude更适合 |
| 量化交易者 | 值得尝试 | 数学建模能力突出,但代码生成需要配合其他工具 |
| AI重度用户/研究者 | 推荐 | 多模态+Deep Think的组合在研究场景无敌 |
4.2 我的实际使用策略
作为一个同时订阅了Claude MAX和Google AI Ultra的用户(是的,每月光AI订阅就超过$450),我的使用策略是:
日常编码 → Claude Code + Opus(主力)
数学推理/科学分析 → Gemini Deep Think(专用)
创意写作/内容生成 → Claude Opus 或 GPT-5.2(看心情)
多模态分析(视频+文档) → Gemini Deep Think(独家)
快速原型/前端开发 → GPT-5.2 Codex(快)
没有一个模型能通吃所有场景。2026年的正确姿势是:按场景选模型。
这个观点我在《AI使用姿势演进》里详细展开过——当年从”只用ChatGPT”到”多模型组合拳”,是AI使用效率的一次质变。
五、Deep Think背后的技术野心:Aletheia和AI驱动的科学发现
Google DeepMind在发布Deep Think的同时,还透露了一个更具野心的项目:Aletheia——一个基于Deep Think推理能力的自主数学研究Agent。
这意味着什么?
不再是”人类提出问题,AI回答问题”,而是“AI自己提出数学猜想,自己尝试证明,自己验证结果”。
Deep Think在国际数学奥赛上拿到金牌级表现(81.5%),在物理奥赛理论部分拿到87.7%——这些不是简单的”刷题能力”,而是面对从未见过的全新问题的推理能力。
如果Aletheia能成功,它可能是AI真正进入”科学发现”领域的起点。
这让我想到r/singularity上的一个讨论:有人把Deep Think称为“下一阶段AI的预览”——不再是更快地回答问题,而是更深地理解问题。
六、2026年2月的AI格局:三足鼎立
站在2026年2月13日这个时间点,AI推理模型的格局已经清晰:
| 维度 | Google Gemini 3 Deep Think | Anthropic Claude Opus 4.6 | OpenAI GPT-5.2 |
|---|---|---|---|
| 推理之王 | ★★★★★ | ★★★★ | ★★★ |
| 编码实战 | ★★★ | ★★★★★ | ★★★★ |
| 创意写作 | ★★★ | ★★★★★ | ★★★★ |
| 多模态 | ★★★★★ | ★★★ | ★★★★ |
| Agent能力 | ★★★ | ★★★★★ | ★★★★ |
| 生态完整度 | ★★★ | ★★★★ | ★★★★★ |
| 性价比 | ★★ | ★★★ | ★★★★ |
注:本表“性价比”仅比较旗舰模型能力与价格(Deep Think / Opus 4.6 / GPT-5.2),不包含Claude Pro等基础订阅套餐。
 2026年2月的AI格局:Google主攻推理深度,Anthropic主攻Agent生态,OpenAI主攻通用体验
2026年2月的AI格局:Google主攻推理深度,Anthropic主攻Agent生态,OpenAI主攻通用体验
每家都有自己的”杀手锏”,也都有明显的短板。
这对用户来说其实是好事——竞争越激烈,进步越快,价格越低。
回想一下:2024年初,GPT-4还是独孤求败;2025年,Claude开始在编码领域反超;2026年,Gemini在推理领域杀出重围。
AI的进化速度已经超过了大多数人的认知更新速度。
七、写在最后:从”能用”到”会用”
用了一天Deep Think,我最大的感受不是”这个AI好厉害”,而是——
选对工具,比工具本身更重要。
Deep Think在数学和科学推理上碾压一切,但让它写博客,它就变成了一个过度分析的学究。Claude Opus在编码和Agent任务上所向披靡,但让它做复杂数学,它就不如Deep Think那么”敢想”。
这就像你不会用锤子去拧螺丝,也不会用螺丝刀去钉钉子。
2026年,AI已经不再是一个工具,而是一个工具箱。你需要知道的不是”哪个AI最强”,而是”这个任务该用哪个AI”。
如果你也在纠结该订阅哪个AI——
- 只需要一个: Claude Pro($20/月),性价比之王
- 需要深度编码: Claude MAX($100-200/月),编码无敌
- 需要深度推理: Google AI Ultra($249.99/月),Deep Think独一档
- 需要全面通用: GPT-5.2 Pro($200/月),没有短板
当然,你也可以像我一样,全都要。然后每个月看着信用卡账单沉默。
2026年2月13日,周五。
Gemini-3 Deep Think正式上线后的第二天。
AI不再只是”回答问题的工具”,它开始”思考问题”了。而我们需要学会的是——什么时候让它快速回答,什么时候让它慢慢思考。
参考资料
- Google DeepMind - Gemini Technologies - Gemini模型家族官方介绍
- Google Blog - Gemini 3 Deep Think 发布公告 - 官方发布博客
- Reddit r/singularity - Gemini-3 DeepThink讨论 - 社区讨论
- ARC Prize Foundation - ARC-AGI-2基准测试验证
- Codeforces - 竞赛编程Elo评分来源
相关阅读
AI深度分析系列
- 月耗17亿Token,阵亡13个账号:一个独立开发者的AI军备竞赛实录 - AI使用成本全透明
- 通用AGI工具已经到来 - Claude Code深度分析
- 你觉得AI不行?也许是你的’使用姿势’还停在2023年 - AI使用姿势演进
AI量化系列
- AI量化交易实战(三):多智能体Prompt工程实战手册 - Prompt工程深度指南
- AI量化交易实战(二):11个大模型,我该选哪个? - 大模型选型指南
工具与生态系列
- Claude Code 官方插件全解析 - 插件生态指南
- AI小白必读:Agent、Skill、MCP到底是什么? - AI入门教程
联系方式
如果你也在使用Gemini Deep Think,特别想交流:
- Deep Think在你的场景下表现如何?
- 你的多模型组合策略是什么?
-
对输出Token缩减有什么应对方法?
- 邮箱:[email protected]
- 微信:winnielove2020
- 博客:https://junxinzhang.com
关注我,持续分享 AI 认知、洞察与实战经验。
在这个AI推理能力指数级增长的时代,选对工具比拥有工具更重要。