今天,DeepSeek 放了一颗大的。
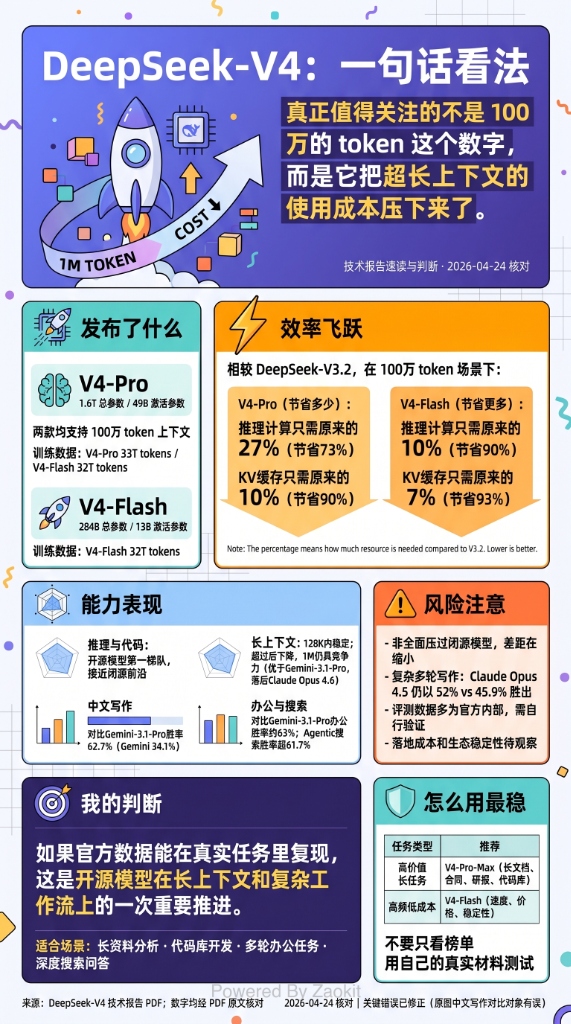
不是小版本迭代,不是 API 降价——是整个 V4 系列正式发布并同步开源。 V4-Pro 1.6T 总参数、100 万 token 上下文窗口、Agentic Coding 开源 TOP1。
而价格?依然很 DeepSeek。 V4-Flash 缓存命中仅 0.2 元/百万 token,输出才 2 元——便宜到不像旗舰系列。
说实话,这是开源模型第一次让人觉得:闭源的天花板,真的被摸到了。

一、两款模型,一个目标:100 万 token 平民化
V4 系列分两款:V4-Pro(旗舰) 和 V4-Flash(高效),都是 MoE 混合专家架构,都支持 100 万 token 上下文。
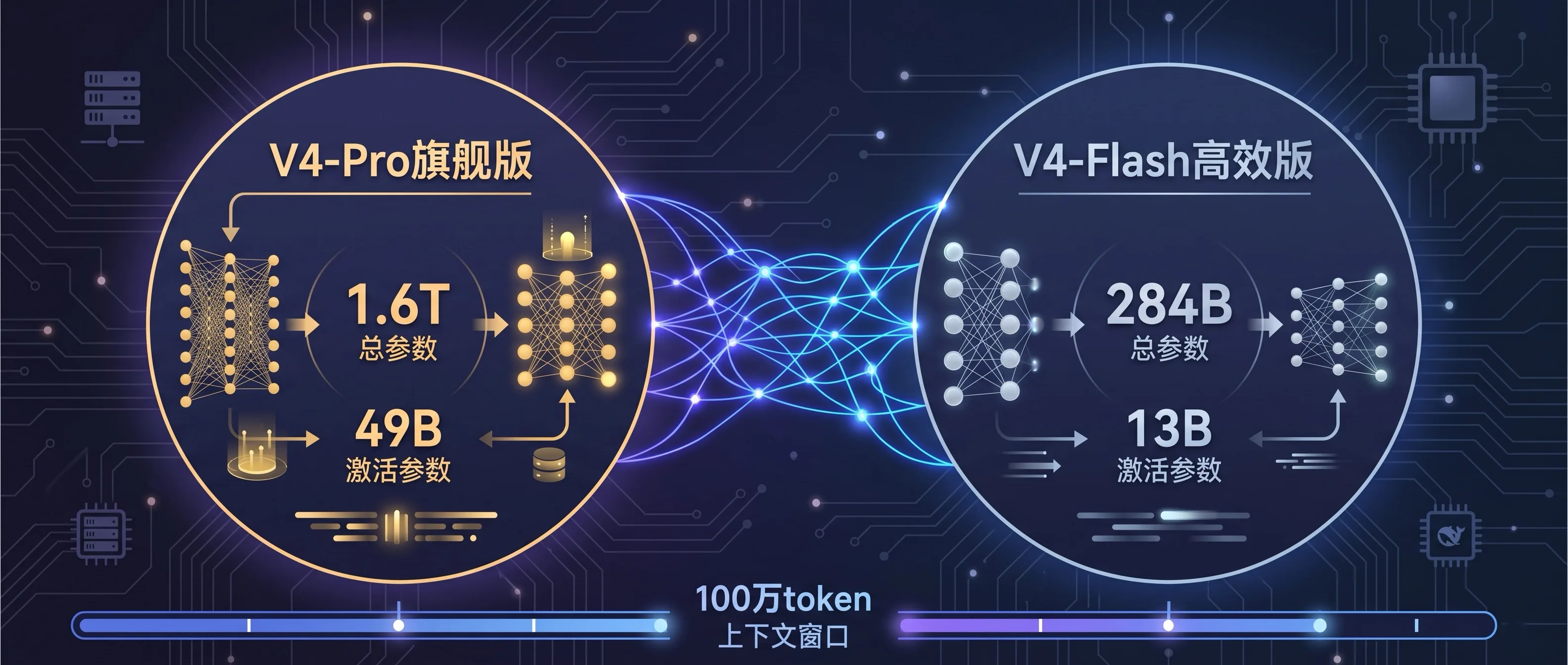
| 指标 | V4-Pro | V4-Flash |
|---|---|---|
| 总参数 | 1.6T | 284B |
| 激活参数 | 49B | 13B |
| 上下文 | 100万 token | 100万 token |
| 定位 | 尖端推理/Agent | 高频低延时 |
| 开源协议 | MIT | MIT |
100 万 token 不再是噱头——V4 的技术突破让它真正可用了。 过去 100 万上下文的模型,算力和内存开销大到不实际。V4 用全新注意力机制把这个问题解了。
二、技术核心:先压缩,后选择
V4 最硬的技术不是参数量,而是混合注意力机制——CSA(压缩稀疏注意力)+ HCA(重度压缩注意力)交叉叠层。
CSA 做精准检索: 在序列维度 4 倍压缩,每个查询只关注 Top-k 相关块——像大海捞针,先把海水抽掉 75%。
HCA 做全局覆盖: 128 倍极致压缩,用极低算力维持长序列连贯性——不看细节,但保持全局意识。
结果是什么?在 100 万 token 场景下:
| 对比 V3.2 | V4-Pro | V4-Flash |
|---|---|---|
| 推理算力 | 仅需 27% | 仅需 10% |
| KV 缓存 | 仅需 10% | 仅需 7% |

翻译成人话:同样处理 100 万 token,V4 的电费和显存占用只有 V3 的零头。 这不是参数堆出来的进步,是架构层面的范式突破。
Needle-in-a-Haystack 测试得分 97%,远超传统稠密注意力的 84% 基线。长文本不仅能塞进去,还能精准找到关键信息。
三、Agent 能力登顶:开源模型的里程碑
这次 V4 最让圈内人兴奋的,不是参数、不是上下文——是 Agentic Coding 能力。
V4-Pro 在 Agent 评测中达到开源模型 TOP1,使用体验优于 Claude Sonnet 4.5,交付质量接近 Claude Opus 4.6 非思考模式。

已经适配了主流 Agent 框架:Claude Code、OpenClaw、OpenCode、CodeBuddy——拿来就能用。 同时支持思考/非思考双模式,你可以根据场景灵活切换推理深度和响应速度。
在数学、STEM、竞赛代码等硬核任务上,V4-Pro 超越了所有已公开的开源模型,表现比肩世界顶级闭源模型。
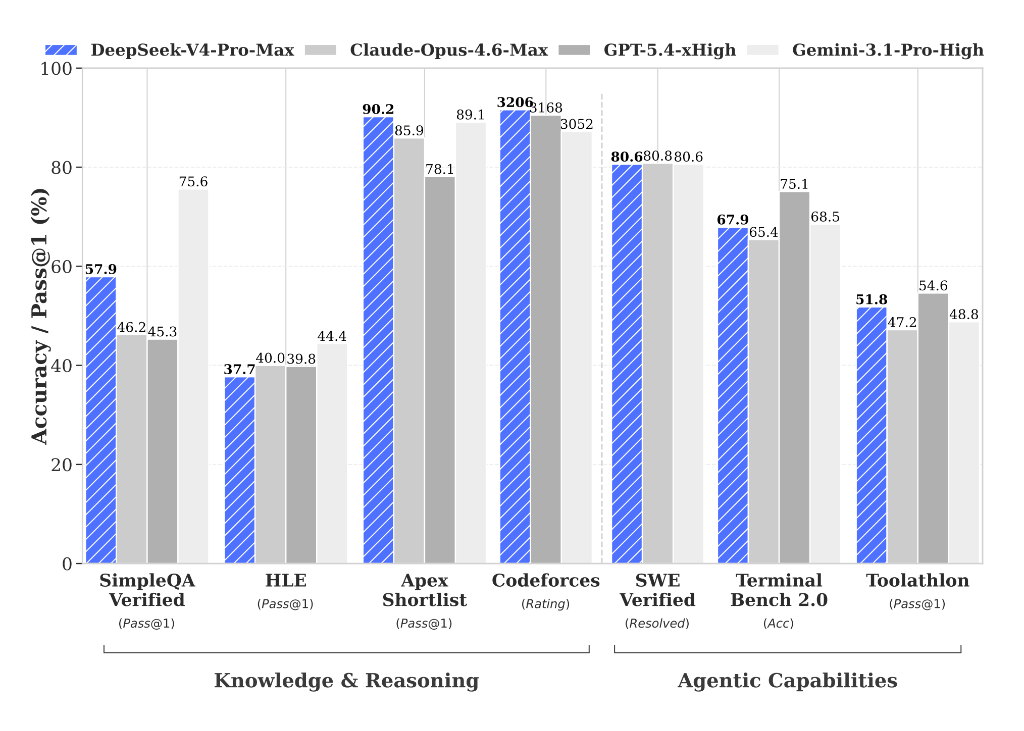
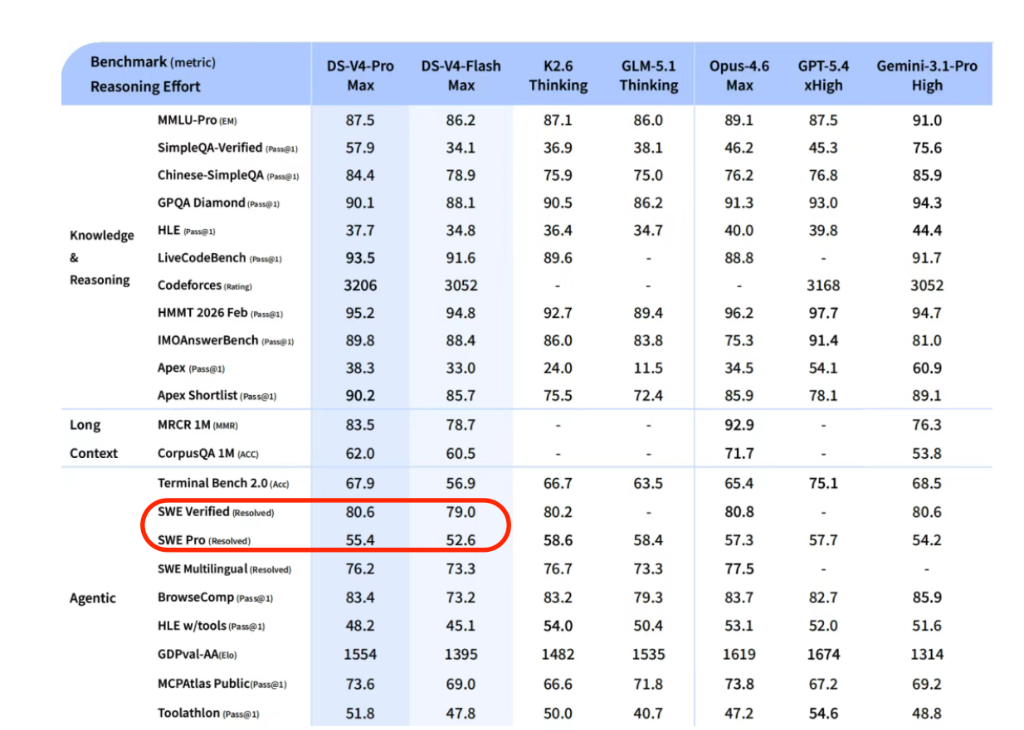
官方在技术报告中明确表示:V4 已成为公司内部员工使用的 Agentic Coding 模型,评测反馈体验优于 Sonnet 4.5,交付质量接近 Opus 4.6 非思考模式,但仍与 Opus 4.6 思考模式存在一定差距。

这意味着什么?开源用户第一次不需要在 Agent 能力上妥协了。 以前选开源,等于接受”差一档”;现在 V4-Pro 直接跟闭源打平手。
四、价格依然很 DeepSeek:V4-Flash 比 V3 还便宜
DeepSeek 的定价策略一如既往——让你觉得不好意思不用。
| 模型 | 输入(缓存命中) | 输入(缓存未命中) | 输出 | 上下文 |
|---|---|---|---|---|
| V4-Flash | 0.2元/M | 1元/M | 2元/M | 100万 |
| V4-Pro | 1元/M | 12元/M | 24元/M | 100万 |
V4-Flash 的输入价格低到离谱——缓存命中仅 0.2 元/百万 token,输出也才 2 元。 这是目前市场上性价比最高的百万级上下文模型,没有之一。
V4-Pro 贵一些,但考虑到它 1.6T 参数和接近闭源旗舰的性能,这个定价在业界几乎没有对手。需要注意的是:受限于高端算力,目前 Pro 的服务吞吐有限,预计下半年昇腾 950 超节点批量上市后,价格会大幅下调。
五、私有化部署:V4-Flash 是最优解
对企业用户来说,V4 的私有化部署成本也有惊喜。V4-Flash 只需 284B 参数、FP4+FP8 混合精度,单节点可部署,显存需求仅约 250GB——比 V3 的 800GB 减少 69%。
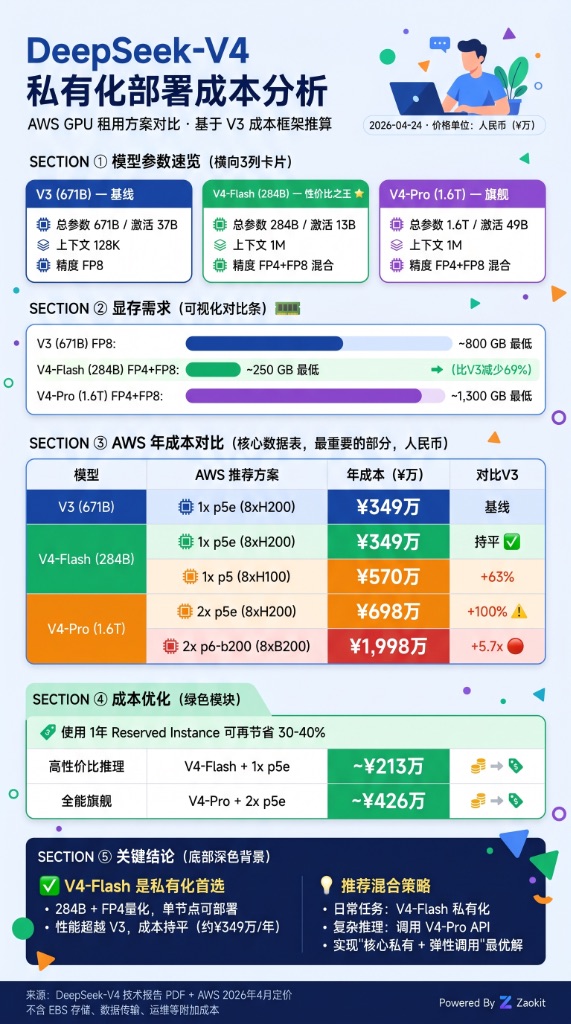
推荐混合策略:日常任务用 V4-Flash 私有化(年成本约 349 万),复杂推理调 V4-Pro API。 核心私有 + 弹性调用,这是当下最务实的长上下文解决方案。
六、风险提示:不要只看榜单
DeepSeek 的技术报告写得很漂亮,但有几点需要冷静看:
- 复杂多轮写作,Claude Opus 4.5 仍以 52% vs 45.9% 胜出——V4 还没有全面碾压闭源
- 评测数据多为官方内部,需要社区独立验证
- 落地成本和生态稳定性,需要时间观察
不过在中文写作能力上,V4-Pro 对比 Gemini-3.1-Pro 的优势已经非常明显——3170 个样本中,V4 以 62.65% 的综合胜率压过 Gemini 的 34.10%:
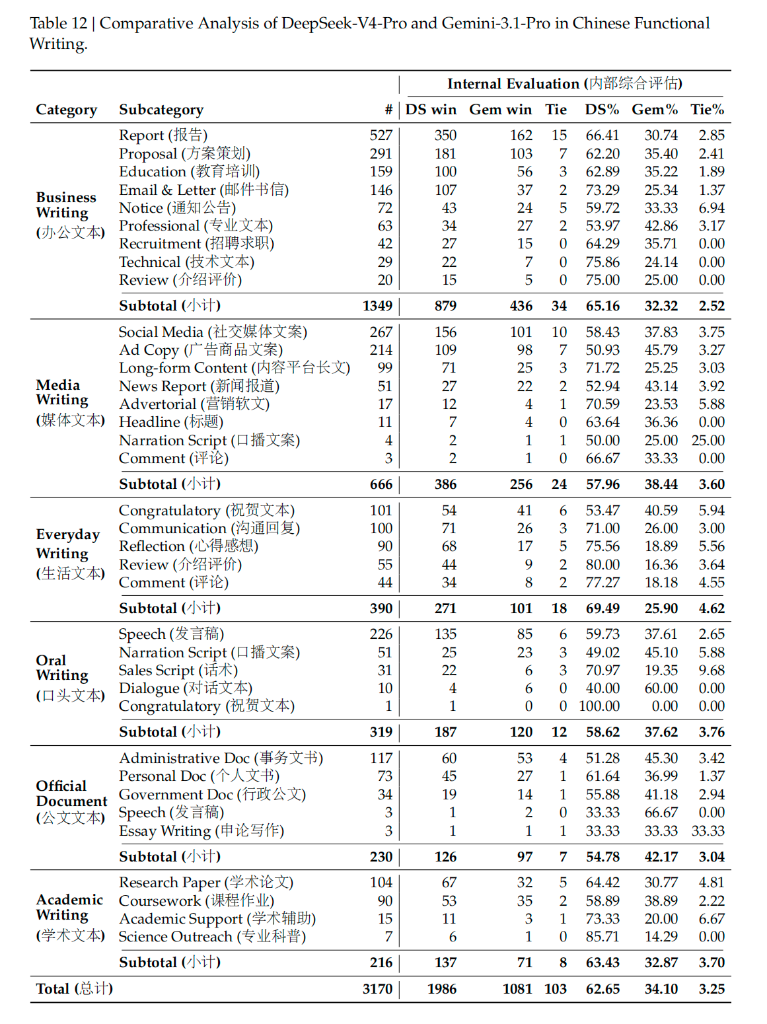
不要只看榜单,用自己的真实材料测试。 榜单是参考,手感才是答案。
写在最后
DeepSeek-V4 证明了一件事:长上下文推理不需要盲目堆算力,而是靠架构创新把成本降一个数量级。 100 万 token 从”实验室玩具”变成了”生产力工具”。
开源追上闭源,不再是口号。V4 是那个让人觉得”开源真的够用了”的拐点。
我一个人打造的 Zaokit AI 正在内测,2026年4月30日前1000名用户赠送价值150RMB的Pro计划,助力大家高效完成图文创作和PPT生成,唯一网站:zaokit.app。
技术在迭代,价格在下降,但你用 AI 建立的认知和工作流——才是真正值钱的东西。