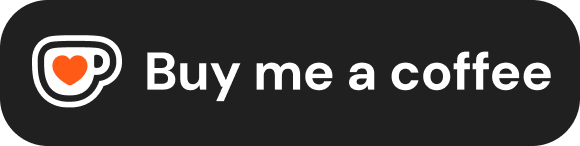你一定有过这种体验:打开 ChatGPT 或 Claude,输入一段话,回车——然后等,等了好几秒,第一个字才蹦出来。但一旦开始,后面的文字就像开了闸一样,噼里啪啦全涌出来。
这不是网络延迟,也不是服务器卡了。这是 Transformer 架构的固有特性。
今天看到 Avi Chawla 在 X 上发了一篇 KV Caching in LLMs 的文章,从第一性原理出发,配动图对比,把这个机制讲得非常清晰。我把核心内容拆开,用更深入的视角重新组织一遍。

一、LLM 怎么生成 token:只有最后一个 token 说了算
先搞清楚一件事:大语言模型不是一次性把整句话吐出来的,而是一个字一个字地「猜」。
Transformer 处理一段输入时,每个 token 都会经过多层注意力计算,产生一个隐藏状态(hidden state)。但关键来了——只有最后一个 token 的隐藏状态,才被用来预测下一个词。
打个比方:你让 10 个人排队传话,但最终只有队尾那个人有权开口说下一句话。前面 9 个人虽然都参与了信息传递,但他们的「发言」只是中间产物。
这就是自回归生成(autoregressive generation)的本质:生成第 N+1 个 token,需要把前 N 个 token 全部喂进模型,跑一遍前向传播,但只取最后一个位置的输出做预测。
问题来了:每生成一个新 token,前面所有 token 都要重新跑一遍吗?
二、Attention 在算什么:Q、K、V 三兄弟
要回答上面的问题,得先理解 Attention 机制里最核心的三个向量:Query(Q)、Key(K)、Value(V)。
在每一层 Transformer 中,每个 token 都会被投影成 Q、K、V 三个向量。计算某个 token 的注意力输出时,需要用它的 Q 去和所有 token 的 K 做点积,得到注意力权重,再用权重对所有 token 的 V 加权求和。
用人话说:Q 是「我想问什么」,K 是「我有什么信息可以回答你」,V 是「我具体能给你的内容」。
当我们要生成第 50 个 token 时,模型用第 50 个 token 的 Q,和前 1~49 个 token 的 K、V 做计算。生成第 51 个 token 时,又要用第 51 个的 Q,和前 1~50 个的 K、V 做计算。
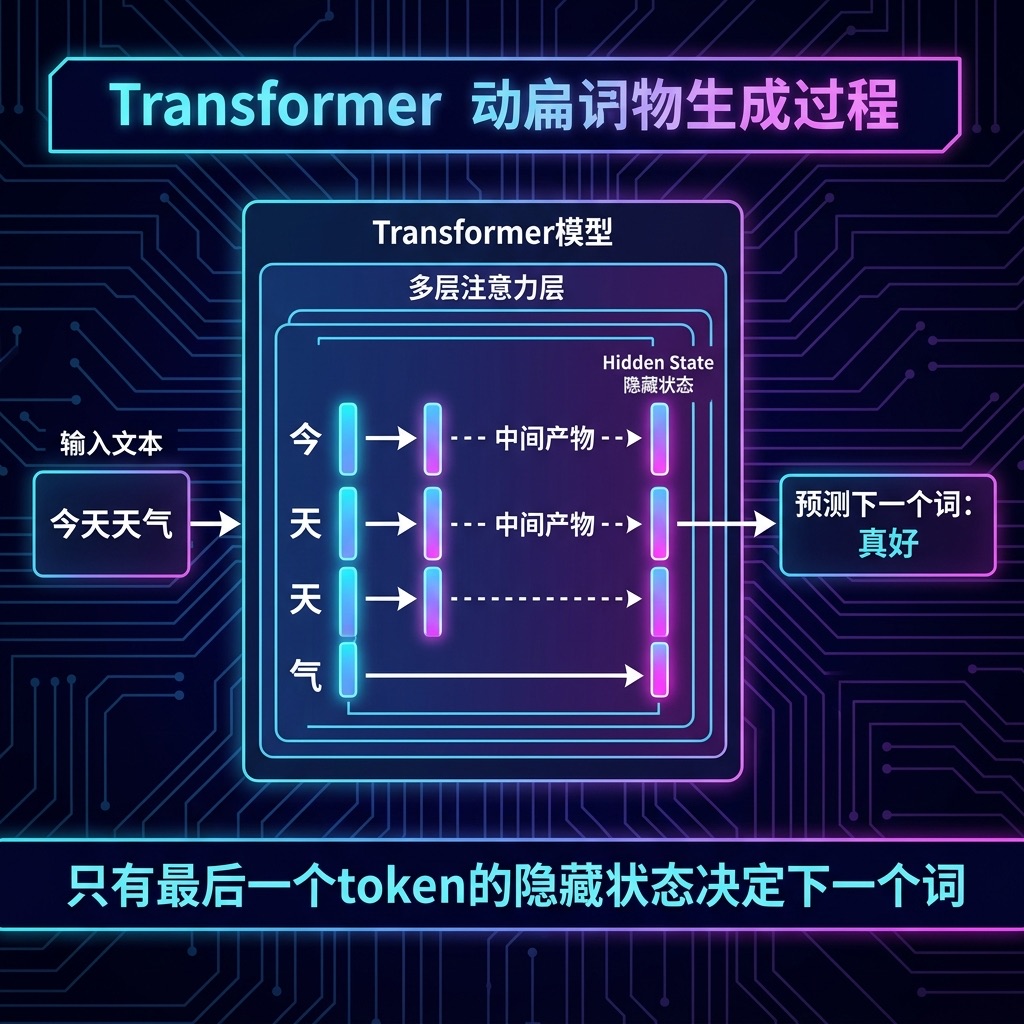
注意到了吗?1~49 的 K 和 V,在生成第 50 个和第 51 个 token 时,是完全一样的。但模型每次都从头重算了一遍。
这就是冗余——O(n²) 级别的计算浪费。
三、解决办法:把 K、V 存起来
思路其实很朴素:既然之前算过的 K、V 不会变,那就别重算了,存起来就好。
具体做法:
- 生成第一个 token 时,正常计算所有输入 token 的 Q、K、V
- 把所有 K、V 存进缓存
- 生成第二个 token 时,只算新 token 的 Q、K、V
- 把新的 K、V 追加到缓存里
- 用新 token 的 Q 对完整缓存(历史 K、V + 新 K、V)跑 Attention
这就是 KV Caching。 一行代码的思路改变,把 O(n²) 的重复计算压成了 O(n)。
你可能觉得这个优化太简单了。但正是这个「太简单了」的思路,成为了今天所有主流推理框架(vLLM、TGI、TensorRT-LLM)的底座。越是基础的优化,影响面越大。
四、为什么第一个字慢:Prefill 阶段的算力暴击
理解了 KV Cache,就能回答文章开头的问题了。

LLM 推理分成两个阶段:
Prefill 阶段(预填充):你发送 prompt 的那一刻,模型要一次性处理整个输入,计算所有 token 的 K、V 并存入缓存。如果你的 prompt 有 2000 个 token,模型就要一口气跑 2000 个 token 的完整前向传播。这是最吃算力的阶段——GPU 满载运算,你在屏幕前干等。
Decode 阶段(解码):KV 缓存建好之后,每生成一个新 token,只需要跑一次单 token 的前向传播。新 token 的 Q 对着缓存跑一遍 Attention,预测出下一个词,追加 K、V 到缓存,循环往复。速度快了一个数量级。
所以体感是:第一个字慢——那是在 Prefill;后面噼里啪啦——那是在 Decode。 你的 prompt 越长,Prefill 越久,第一个字等得越痛苦。
这也解释了为什么有些推理服务会给你一个 TTFT(Time To First Token)指标——它直接衡量 Prefill 阶段的耗时。做私有化部署的同学,优化 TTFT 是最直接提升用户体验的抓手。
五、代价:KV Cache 是显存杀手
天下没有免费的午餐。KV Cache 用计算换内存,代价是显存。

以 Qwen 2.5 72B 为例,粗略估算:模型有 80 层,每层 64 个注意力头,每个头的维度 128。一个 token 在一层中产生的 K、V 各需要 64×128×2(FP16)= 16384 字节。80 层下来,单个 token 的 KV Cache 约 2.5 MB。如果上下文窗口是 4096 个 token,单个请求的 KV Cache 就接近 10 GB。
10 个并发?100 GB 显存光给 KV Cache。模型权重本身才多大?
并发量一大,KV Cache 比模型权重还大。 这就是推理部署中最现实的瓶颈——不是算力不够,是显存不够。
业界为此发明了一系列优化技术:
- GQA(Grouped Query Attention)/ MQA(Multi Query Attention):让多个 Q head 共享 K/V head,大幅减少 KV Cache 的存储量。Llama 3 用的就是 GQA
- Paged Attention:vLLM 的核心创新,把 KV Cache 像操作系统管理内存页一样分块管理,避免碎片化浪费。非连续存储,按需分配
- KV Cache 量化:把 KV 从 FP16 压缩到 INT8 甚至 INT4,牺牲极少精度换更大上下文和更多并发
理解了 KV Cache 的原理和代价,你就理解了整个 LLM 推理优化的底层逻辑。所有主流推理框架——vLLM、TGI、TensorRT-LLM——都是围绕「怎么更高效地管理 KV Cache」做文章。
写在最后
很多人天天用 ChatGPT、用 Claude,但从来没想过「第一个字为什么慢」这个问题。这篇文章推荐给所有正在或即将接触大模型推理的朋友——不需要你会写 CUDA,但你至少应该知道你用的工具里面发生了什么。
KV Cache 看起来是一个很底层的技术细节,但它的影响面覆盖了从用户体验(TTFT)到成本控制(显存占用)到架构选型(GQA vs MHA)的方方面面。做 AI 落地的人,绕不开这个知识点。
原文来自 Avi Chawla 的 X 文章,从第一性原理出发讲得很清楚,配了动图对比,适合不太了解推理优化的同学入门。
我一个人打造的 Zaokit AI 产品 已融入企业工作流,2026 年 5 月 31 日前 1000 名用户赠送价值 150RMB 的 Pro 计划,助力大家高效完成图文创作和 PPT 生成。唯一官方网站:zaokit.app。
最后,如果你认可 Zaokit AI 的产品理念,欢迎后台留言加入我们的社群。我们不卖课、不割韭菜,只聚焦 ToB 企业场景的 AI 落地实战。 希望在这里,能给你带来不一样的思维火花和真实的商业碰撞。