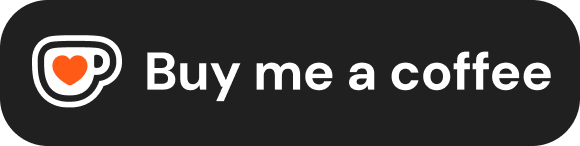这几天连续写了 DeepSeek V4 的压测数据和 H20 显卡的买断报价。后台有很多中小企业老板和 CTO 给我留言,大家的问题非常统一:
「Jason,H20 动辄 190 万一台,我们全年的 AI 预算只有 100 万。在这个预算下,纯私有化场景,我们能落地什么开源模型?比如 GLM、Kimi、Qwen、DeepSeek 这些能跑吗?」
这是个极度务实、极度接地气的好问题。
100 万人民币,在 AI 军备竞赛里也就是硅谷大厂几小时的电费。但在真实世界的企业 IT 预算里,这是一道分水岭。今天这篇文章,我们就把这每年 100 万的预算掰开揉碎,看看在纯私有化场景下,到底能办成什么事。

一、先算算力账:每年100万预算怎么花?
首先,放弃幻想:100 万买不到 8 卡 H20(单台 190 万起步),也买不到满血版的顶级算力集群。
在纯私有化部署中,显存(VRAM)是决定生死的第一指标。没有显存,模型根本启动不了。在每年 100 万的预算下,我们首年大概有 50-60 万可以用来采购硬件基础设施(后续年份可用于扩容或服务升级),剩下的要留给软件授权、实施和运维。
60 万的硬件预算,你有三条高性价比的路径:
- 主流企业级方案:L20 / L40S 60 万硬件预算,保守估算可采购 1 台到 2 台 配置 4 卡 L20(48GB/卡)或 L40S(48GB/卡)的服务器(具体取决于品牌、渠道和售后配置)。单台 4 卡总显存约 192GB,已足够通过张量并行跑起 70B 级别的开源大模型。注意:L40S 价格偏高,60 万内采购 2 台需货比三家,不要过于乐观。
- 性价比极客方案:8 卡 RTX 5090 服务器 60 万足以采购 1 台到 2 台 配置 8 卡 RTX 5090(32GB/卡)的高性能工作站。单机总显存达 256GB,推理吞吐性价比极高,轻松跑 70B 模型;256GB 也是尝试 V4-Flash 量化版的起步显存门槛。
- 国产替代方案:昇腾 910B 体系 在合规和信创要求严格的场景下,60 万可以拿下配备多张昇腾芯片的国产大模型一体机。国产方案现在的适配已经非常成熟,特别是对于国内的开源模型,很多都是原生支持。
结论:首年 60 万硬件预算,单机显存起步 192GB(4 卡 L20),扩展上限约 256GB(8 卡 RTX 5090)。 这是我们下一步挑选模型的物理边界。
二、模型点将谱:GLM、Kimi、Qwen、DeepSeek 怎么选?
基于 192–256GB 的显存边界,我们来看这四款模型在私有化场景下该怎么落地。
1. 业务基石,最全能的生态:Qwen(通义千问)
落地建议:Qwen2.5-72B(INT8 量化版)或 Qwen2.5-32B(全精度) Qwen 最大的优势是开源生态极其繁荣,双语能力和长文本处理非常能打。对于大多数企业来说,如果你要做内部的知识库问答、文档分析,Qwen2.5-72B 的 INT8 量化版本在 192GB 显存下跑得非常流畅,是目前中型企业私有化的万金油首选。
2. 逻辑与代码的极致效率:DeepSeek
落地建议:DeepSeek-R1 蒸馏版(70B);显存达 256GB+ 可进阶尝试 V4-Flash 对于 192GB 显存的机器,DeepSeek-R1 70B 蒸馏版是最稳妥的选择,逻辑推理和代码生成能力已经很强。如果集群显存能达到 256GB 以上,可以尝试 DeepSeek-V4-Flash(284B)的 INT4/INT8 量化部署——但必须认清:V4-Flash 在这个规模机器上是贴着显存上限在跑,高并发和长上下文会继续吃显存,这已经是 100 万预算下纯私有化 Agentic Coding 的能力天花板。在代码辅助生成、复杂逻辑推理或数据清洗场景下,直接上 DeepSeek,它的 Token 效率极高,同等算力下并发量能做到最优。
3. 企业级应用与合规先锋:GLM(智谱)
落地建议:GLM-4-9B 或私有化一体机版本 GLM 在中文环境的语感、函数调用(Function Calling)以及企业级合规方面做得极好。如果你需要让大模型去调用内部 ERP、CRM 系统的接口,GLM-4 的工具调用成功率非常高。
4. Kimi:别再说它纯闭源了
落地建议:Kimi K2/K2.6 可作为私有化候选,但部署门槛较高 Kimi K2 和 K2.6 已在 Hugging Face 上开放模型权重,不能再笼统说”Kimi 是闭源无法本地部署”。准确的说法是:Kimi 线上产品和商业能力仍是闭源服务,但 Kimi K2/K2.6 的开放权重已可作为私有化部署候选。不过其参数规模较大,部署门槛和工程复杂度明显高于 70B 级模型,100 万预算下能否稳定跑起来还要看具体集群配置。

三、私有化落地的三大避坑指南
买好机器、选好模型,只是万里长征第一步。我见过太多企业把机器拉进机房后,跑出来的效果一塌糊涂。请务必避开以下三个坑:
第一,千万不要迷信“不量化的全尺寸模型”。
很多人觉得量化会变傻。但在资源受限的私有化场景下,使用 vLLM 引擎配合 INT8 / FP8 量化,通常能明显降低显存占用。至于速度和精度的变化,不同模型、不同硬件、不同任务差异很大——最稳妥的方式是按你的实际业务场景测一遍基准再下结论。

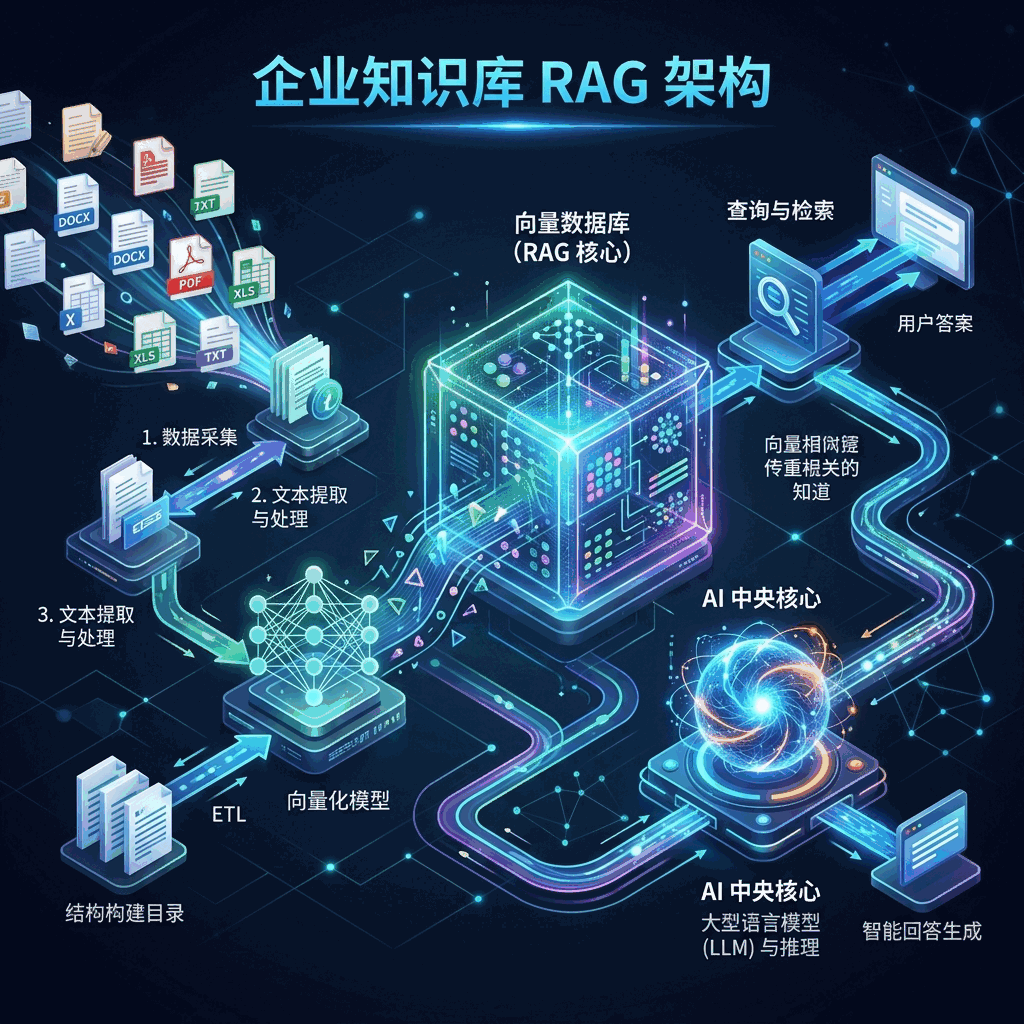
第二,把 30% 的精力放在 RAG(检索增强生成)上。 模型再强,不知道你公司的《2026 年员工手册》也是白搭。不要花钱去微调(Fine-tuning)知识,而是建立一套稳健的 RAG 知识库系统。清理好你的 PDF、Word 和内部 Wiki,把它们向量化存入 Milvus。好数据喂出来的 32B 模型,比乱喂数据的 72B 聪明得多。
第三,警惕“重采购、轻实施”的预算陷阱。 首年的 100 万不要全买铁疙瘩。留出至少 15-20 万,交给专业的实施团队去帮你做系统集成、业务接口开发和首年的运维兜底。大模型是个娇贵的系统,网络、CUDA 版本、驱动匹配,任何一个小问题都能让你的系统停摆。
写在最后
在 AI 时代,大厂有大厂的火力覆盖,中小企业有中小企业的精准狙击。
每年 100 万预算,纯私有化落地,完全可行。 放弃满血 1.6T 的执念,优先选择 Qwen2.5-72B 或 DeepSeek-R1 70B 蒸馏版作稳定底座,显存够用时进阶尝试 V4-Flash,配上 L20 或 RTX 5090 工作站,扎扎实实做好内部数据的 RAG 清洗。这套系统,足够帮你的企业实现研发提效、客服自动化和内部知识问答的初步跃升。
AI 认知与成本永远是正相关的:懂得取舍,用最少的钱办最大的事,这本身就是企业级工程能力的最高体现。
另外,分享一个好消息:我一个人打造的 Zaokit AI 产品 现已全面融入企业工作流。为了感谢大家的支持,2026 年 5 月 31 日前,前 1000 名用户免费赠送价值 150RMB 的 Pro 计划,助力大家高效完成图文创作和 PPT 生成。唯一官方网站:zaokit.app。