这几天我连续写了几篇 DeepSeek V4——技术解读、H20 TCO、买断报价、压测数据,本以为这个系列告一段落。
结果 4 月下旬,好几件大事密集发生:Kimi K2.6(4月20日)、谷歌新一代 TPU(4月22日)、GPT-5.5(4月23日)、DeepSeek V4(4月24日)接连亮相,Anthropic 估值在二级市场悄然超过 OpenAI。模型战争,比我想象的打得更猛。
这一轮热闹的背后,有一个被大多数人忽略的命题值得认真讲清楚:效率,才是这场战争真正的战场。

一、这次同台登场的,不只是 DeepSeek
同一周内,圈子里不只在聊一个模型。密集登场的,是这样一张清单:
- Kimi K2.6(4月20日):Moonshot 推出的新版本,性能指标对标顶线
- 谷歌新一代 TPU(4月22日):训练与推理任务拆分,两款独立芯片应对极致需求
- GPT-5.5(4月23日):OpenAI 发布,开发者社区反馈正向,但价格比 GPT-5.4 贵一倍
- DeepSeek V4(4月24日):支持 100 万 TOKEN 上下文,面向 Agentic Coding 和复杂多步任务,已被报道适配华为昇腾等国产芯片
- Anthropic 二级市场估值:悄然超过 OpenAI,二级市场对 OpenAI 的需求转弱,Anthropic 更受追捧
这个场面让我想起硅谷圈里流行的一句话:「DeepSeek 带来的最大风险,不是它打败了谁,而是它为所有闭源模型公司画了一条生死线。」
一旦开源模型能够超越某家闭源公司,那家公司的估值逻辑会被严重压缩——产品、渠道和企业客户的价值仍在,但「更强的模型卖更贵」这条商业路径就基本走不通了。
二、DeepSeek V4 的工程完成度,超出预期
大方向在意料之内,但工程完成度有非常大的惊喜。
过去两年,DeepSeek 一直在做一件事:在更强的资源约束下,比所有人更激进地追求 TOKEN Efficiency (词元效率)。 这次 V4 是这条路线的集大成之作。
技术报告里着重强调的三个核心突破:
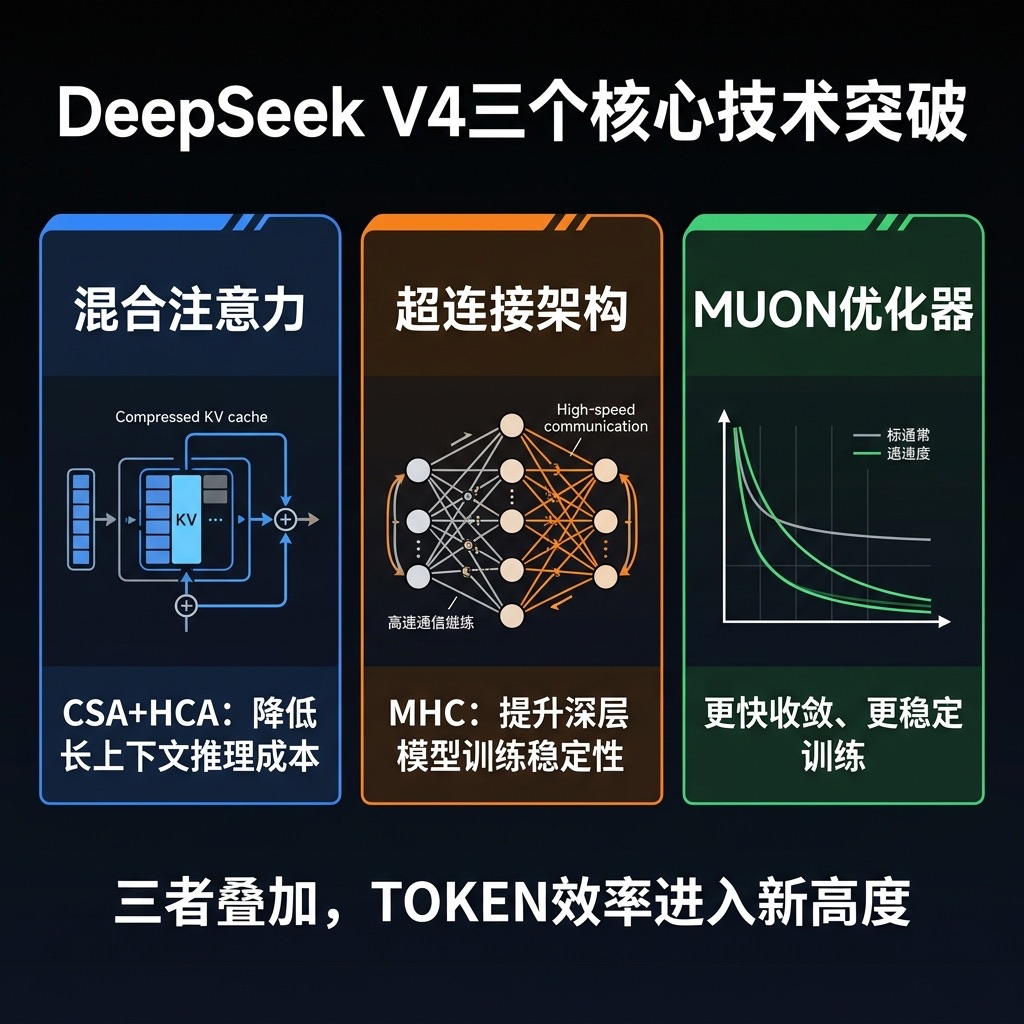
第一,混合注意力机制(CSA + HCA + Sliding Window)
解决的核心问题是:长上下文推理的 Attention 成本和 KV Cache 占用。传统 Attention 机制下,处理整段长文本时计算量随上下文长度增长非常快,生成每个新 TOKEN 也都受前面全部上下文影响——上下文越长,开销越大。
CSA(Compressed Sparse Attention)把多个历史 TOKEN 的 KV Cache 压缩成一个 Compressed KV Engine,再通过稀疏 Attention 检索最相关的部分——精确搜索,而不是全量计算。 HCA(Heavily Compressed Attention)则做全局的快速低精度检索。两者加上 Sliding Window 的近邻强相关补充,三层机制合力,大幅降低长上下文推理成本。
第二,MHC 超连接架构(Manifold Constraint Hyper Connections)
原来 ResNet 式的 Residue Link 是单条高速通路;HC 把它扩展成多条;Manifold Constraint 在多条通路上加数值稳定性约束。三者叠加,让深层模型训练更稳定——这是能够把这么多小技术「拼接在一起训稳」的关键。
第三,MUON 优化器
提升训练收敛速度和稳定性,让更大、更复杂的模型可以跑出来。注意:MUON 并非完全替代 Adam,部分模块仍保留 Adam——这是一种精心调配的混合策略,不是一刀切。
三者叠加的结果:V4-Pro 在 100 万 TOKEN 长上下文场景下,技术报告给出的数据是计算开销降到上一版约 27%,KV Cache 占用降到约 10%。
三、效率是到达 AGI 的必经之路,不是另一条路
这是我觉得这次讨论里最值得认真讲的一个判断。
很多人会问:追求 TOKEN Efficiency 和追求更强的 AGI,是两条技术路线吗?
答案是:恰恰相反。TOKEN Efficiency 是达到 AGI 或更强 Agentic 系统的基础条件,不是替代方案。

逻辑很清晰:未来更强的模型,不只是参数更大,而是需要更多的 Test Time Compute、更长的推理链、更长的上下文、更复杂的工具调用、更长时间的任务连续性。
Agent 时代,每个任务消耗的 TOKEN 是 chatbot 时代的 10 倍甚至 100 倍。
没有效率,AGI 就只能是个 Demo;有了效率,AGI 才能成为真正的产品和基础设施。
用芯片架构师的视角说得更直接:模型效率是模型与硬件协同设计的结果。DeepSeek 的论文里甚至给硬件厂商提出了建议——比如 GPU 之间的互联带宽并不是越高越好,超过特定阈值后,更多芯片面积放在通信而不是计算,反而拖慢效率。这种「倒逼硬件」的研究视角,是硅谷顶尖实验室因为资源充足而往往忽略的。
四、英伟达短期无忧,但市场结构正在改变
DeepSeek V4 适配华为昇腾等国产芯片的报道,引发了「英伟达要被取代」的讨论。这个判断需要更精准地区分。
短期来看,英伟达不会被取代。
英伟达的护城河不只是 GPU,而是整个生态:CUDA 软件栈、NVLink 高速互联、NCCL 通信库、成熟的供应链和开发者社区。英伟达一直强调的核心观点是:即使同等性能的芯片价格降到零,也很难在短期内撼动其在训练场景的主导地位。
但长期来看,推理市场的格局正在分化。
DeepSeek V4 通过混合注意力机制,大幅降低了长上下文推理对 Compute 和 KV Cache 的需求。这让许多非英伟达芯片——不只是国产芯片,包括 AMD、Google TPU、以及各大云厂商的自研推理芯片——有机会在推理场景承接更多 workload。
谷歌 TPU 的案例已经证明了这件事:把 Gemini 和 Claude 跑在 TPU 上可行,只要你对模型-硬件-软件栈有全栈掌控。这种模式对独立芯片公司很难复制,但对有全栈能力的大公司是可行路径。
未来的数据中心推理基础设施,不会是「一张卡打天下」,而是训练、推理、长上下文、Agentic workload 各用最合适的芯片。 这个异构趋势已经是现在进行时,不是远期预测。
五、硅谷的觉醒:效率是智能的组成部分
从 Jenny Xiao(硅谷 Lion’s Capital 合伙人,OpenAI 前研究员)的视角看,DeepSeek V4 对硅谷的真正冲击,不是某个 Benchmark 分数——
而是它让整个硅谷开始重新思考一个问题:效率和智能,到底是什么关系?

硅谷最大的结构性问题是:闭源模型公司长期把商业模式建立在「更高智能卖更贵」上,因此对算法效率的投入是系统性不足的。DeepSeek 恰恰处于算力受限的环境,被「倒逼」走上了效率创新之路——结果反而让它在这个维度一骑绝尘。
这就是 DeepSeek 的结构性优势:资源约束创造了算法创新的压力,反而成了竞争力的来源。
在 Anthropic vs OpenAI 的战局里,这个逻辑也在另一个层面上演:Anthropic 专注、节制、聚焦 Enterprise 和 Coding;OpenAI 多线作战、算力扩张激进,结果二级市场有机构在减持 OpenAI,而 Anthropic 估值已在二级悄然超越。效率意识,不只是工程上的事,也是公司策略上的事。
六、模型竞争的下一轮,比的是什么
梳理完这一轮,我对下一阶段竞争的判断是:
比参数规模的时代正在结束,比 TOKEN Efficiency 的时代已经开始。
具体来说,接下来的竞争焦点会集中在:
- 模型架构 × 硬件协同:谁能更好地让模型适配硬件,谁的推理成本就更低
- 长上下文 KV Cache 管理:Agentic 时代的核心瓶颈,谁压得住谁就能跑更大的任务
- Agentic Workflow 的 TOKEN 预算管理:每个 Agent 都需要一个 TOKEN Budget Manager,这是一个尚未被充分开发的优化空间
- 非英伟达芯片的推理适配:推理市场异构化,谁先完成软件栈适配谁就先抢到推理收益
这不是两条路的选择,而是同一条路上,比谁能跑得更快、跑得更省。
写在最后
这几天连续写了好几篇 DeepSeek V4——从技术解读,到 TCO,到买断报价,到压测数据,到今天的市场格局。
V4 发布这件事,比「又出了一个强模型」意味着更多。它让大家看到:大模型竞争正在从单点 Benchmark 变成系统竞争,模型架构、TOKEN Efficiency、芯片适配、软件栈、商业化开源生态,正在成为同一场战争的不同战场。
没有效率,AGI 就只是个演示品;有了效率,AGI 才能真正成为产品和基础设施。DeepSeek V4 做的事情,不是打败了谁——它是在重新定义这场战争的评判标准。
我一个人打造的 Zaokit AI 正在内测,即日起前1000名用户赠送价值150RMB的Pro计划,助力大家高效完成图文创作和PPT生成,唯一网站:zaokit.app。
相关阅读
- DeepSeek V4-Pro 在 8×H200 141GB 上的实测:617K TPM 从哪来
- DeepSeek-V4 私有化买断 GPU 要多少钱?两套方案,价格我都算好了
- DeepSeek-V4 私有化部署到底要花多少钱?一台 H20 就够了
- DeepSeek-V4 发布:开源模型的 Agent 能力,第一次摸到了闭源的天花板
📺 推荐观看:本文核心观点来自硅谷101播客的深度讨论,强烈推荐看完整视频——《DeepSeek V4 来了,模型战争重燃》— 硅谷101,芯片架构师肖志斌与 OpenAI 前研究员 Jenny Xiao 的一手硅谷视角,干货密度极高。