上周写完翁家翌那篇后,很多人私信问我:“他到底做了什么?Codex 又是怎么回事?”
今天把这个问题彻底说透。
结论先行:2026 年大模型的胜负手,不是谁的模型更强——而是谁的 AI Infra 迭代更快。Codex 就是这个结论的活体证据。

一、翁家翌级别的智商,在 Codex 背后不止一个
先说一个很多人忽略的事实:Codex 不是一个”产品团队”做出来的,是 OpenAI 最核心的工程力量打造的。
翁家翌在访谈里提到一个关键判断——“对 OpenAI 来说,生死线是 infra 迭代速度。” 这不是客套话。他本人就是这条生死线上的核心人物:ChatGPT 发布贡献名单第六位,从 GPT-3.5 到 GPT-5 全程参与。
但翁家翌不是孤例。Codex 团队的工程密度,可能是全球 AI 公司里最高的。
| 维度 | Codex 团队特征 |
|---|---|
| 人才来源 | 清华/CMU/MIT 等顶尖院校,强化学习+系统工程双重背景 |
| 核心能力 | 不是”会用模型”,是”会造模型运行的地基” |
| 产出标准 | 翁家翌的标准:最大化在 OpenAI Blog 上出现名字的次数 |
| 选择逻辑 | 放弃谷歌高薪,选人才密度最高的地方 |
你可以绝对信任 Codex 的工程能力——因为造它的人,和翁家翌是同一个 level。 他们不是在”做产品”,是在把整个 AI 研发管线变成可以自我加速的引擎。
二、模型趋同:一个不可逆的事实
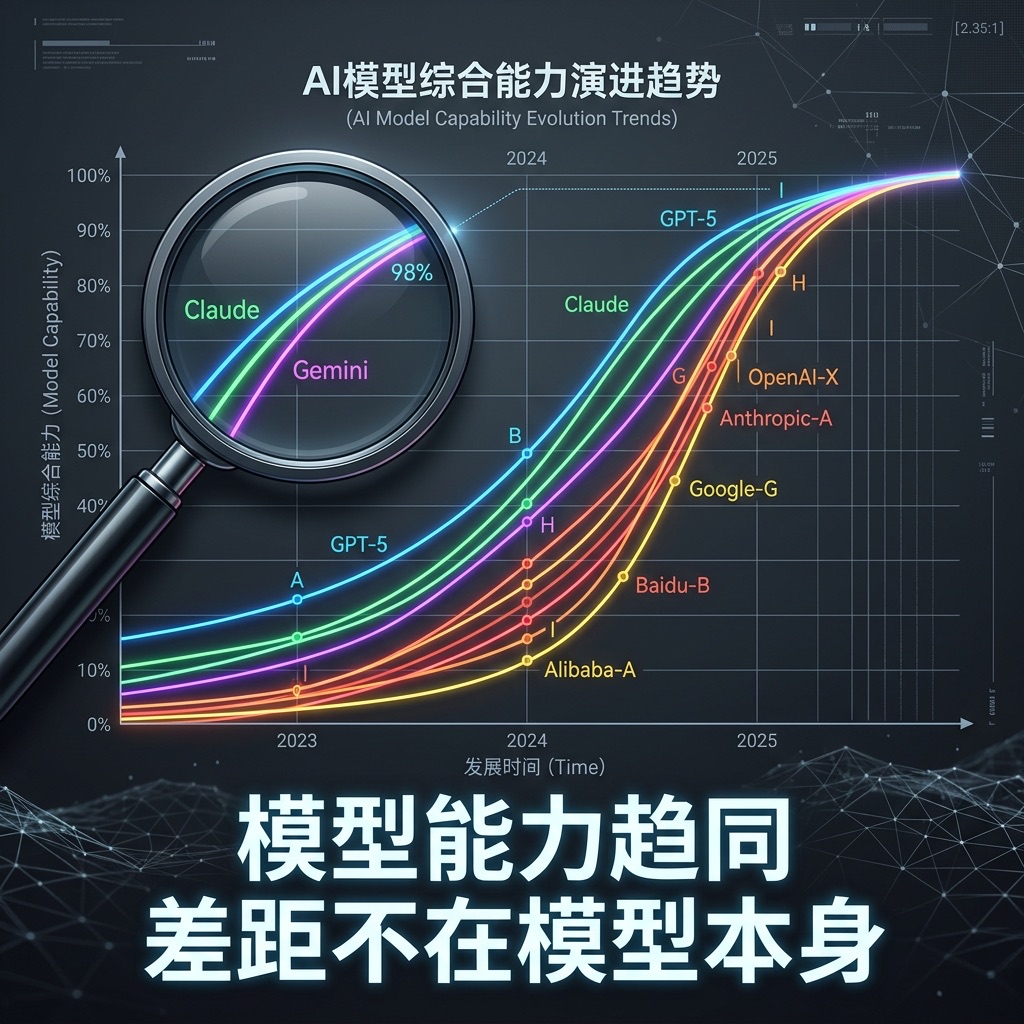
说完人,说趋势。2026 年最重要的行业共识:顶级大模型的能力差距,已经小到不值得讨论。
GPT-5、Claude Opus、Gemini Ultra——在主流基准测试上的差距已缩小到 2–5 个百分点。半年前你还能说”某家模型明显更强”,现在这句话越来越难以成立。
| 对比维度 | 2024 年 | 2026 年 |
|---|---|---|
| 顶级模型差距 | 代际级(GPT-4 远超竞品) | 个位数百分点 |
| 模型迭代周期 | 12–18 个月 | 3–6 个月 |
| 决定性因素 | 模型架构+数据规模 | Infra 迭代速度 |
| 竞争焦点 | “谁的模型更聪明” | “谁能更快把能力变成产品” |
这意味着什么?模型本身正在商品化。 就像 CPU 性能差距越来越小之后,操作系统和软件生态变成了胜负手。大模型的”操作系统”,就是 AI Infra。
三、Infra 迭代速度:看不见的核心竞争力
翁家翌在访谈里有一句话,被大多数人直接跳过了:
“AI 实验室最稀缺的不是算法研究,是能支持大规模、高效迭代的 Infra 人才。”
这句话的含金量极高。翻译成大白话就是:模型再强,如果跑不起来、跑不快、跑不稳——等于零。
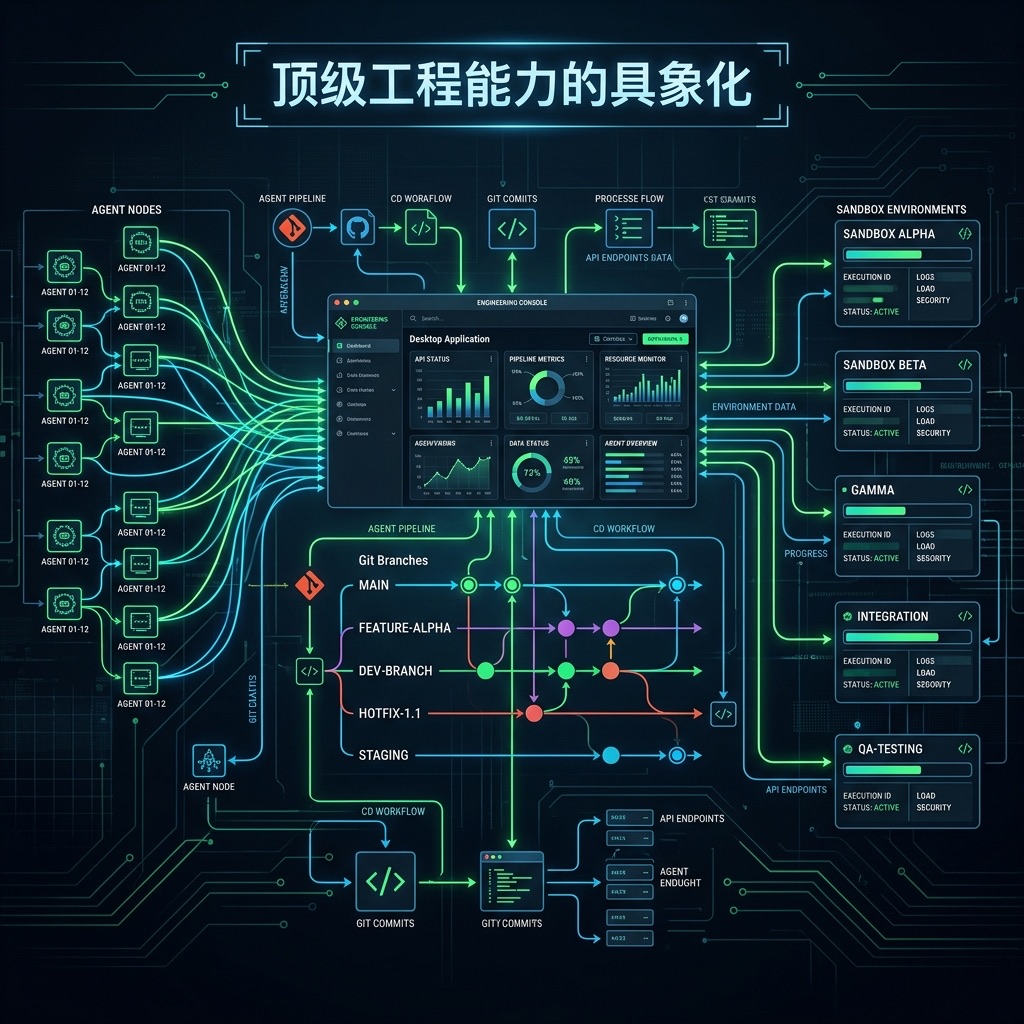
Codex 的架构设计就是这个思维的产物。2026 年 2 月发布的桌面版,技术栈完全围绕”迭代速度”展开:
统一 App Server 架构——Web、CLI、桌面、IDE 扩展全部共享同一套后端,服务端更新无需客户端升级。三个核心原语:Item(原子输入输出)、Turn(单次 Agent 工作序列)、Thread(持久化会话容器)。
原生多 Agent 编排——不是”聊天窗口”,是”Agent 指挥中心”。支持并行运行多个 Agent,按项目和线程组织,互不干扰。
OS 级沙箱隔离——macOS 系统级沙箱,Windows 使用受限令牌+文件系统 ACL。Agent 的每次操作都在隔离环境中执行,Git worktree 自动隔离分支变更。
这些不是花哨的功能列表——是工程能力的具象化。 能把这套系统做到稳定运行,需要的不是”会调 API”的人,是翁家翌这个 level 的系统工程师。
| 传统 AI 编码工具 | Codex 架构 |
|---|---|
| 单次请求-响应 | 长程 Agentic 会话 |
| 客户端逻辑为主 | 服务端 App Server 驱动 |
| 手动管理上下文 | Thread 自动持久化 |
| 单 Agent 串行 | 多 Agent 并行编排 |
| 无隔离 | OS 级沙箱 |

四、为什么 Infra 速度决定了大模型公司的命运?
把上面的逻辑串起来:
模型趋同 → 模型本身不再是护城河 → 谁能更快迭代 Infra → 谁能更快把模型能力变成稳定产品 → 谁赢。
翁家翌在 OpenAI 的核心工作,就是把强化学习从学术界的”小作坊”任务(Atari、MuJoCo)提升到工业级、可扩展的规模。他构建的 RLHF 流水线,决定了 OpenAI 单位时间内能修复多少 bug、跑多少实验、推出多少产品迭代。
这才是 Codex 能从桌面应用、CLI、IDE 扩展、Web 四个端同时推进的底层原因——不是人多,是 Infra 足够快。

OpenAI 正在从 4500 人扩张到 8000 人,增长重心就是工程和基础设施团队。他们雇了专门的工业算力负责人来管理全球数据中心扩张,同时自研 AI 原生芯片。不是在做产品——是在建数字时代的铁路和发电厂。
还有一个反直觉的事实:Codex 现在跑在 GPT-5.4 和 GPT-5.4 mini 上。 从 GPT-3.5 到 GPT-5.4,中间迭代了多少个版本?每次迭代背后,都是 Infra 团队让整条管线跑得更快的结果。翁家翌说”教 researcher 做好 engineering,要远比教 engineer 做好 research 难得多”——因为 Infra 是不可速成的肌肉记忆。
五、对我们的启示
第一,选 AI 工具别只看模型排行榜。 模型都差不多了,关键看工具背后的工程团队能不能持续迭代。Codex 每周都在推更新,因为 Infra 撑得住这个速度。
第二,AI 创业的护城河不在模型。 如果你在做 AI 产品,模型随时可以换——但你的 Infra 架构、数据管线、Agent 编排系统是换不了的。这才是真正的壁垒。
第三,个人技能树要往 Infra 方向长。 翁家翌放弃 PhD、放弃谷歌,选了”最不确定”的 OpenAI。他的判断:Infra 离真实产品最近。 会调 API 的人 2024 年就饱和了,会造 Infra 的人 2026 年依然极度稀缺。
写在最后
回到那句被大多数人跳过的话:“对 OpenAI 来说,生死线是 infra 迭代速度。”
这不只是 OpenAI 的生死线——是所有大模型公司的生死线。模型会趋同,但 Infra 不会。能造铁路的人,永远比坐火车的人值钱。
我一个人打造的 Zaokit AI 正在内测,2026年4月30日前 1000 名用户赠送价值 150 RMB 的 Pro 计划,助力大家高效完成图文创作和 PPT 生成,唯一网站:zaokit.app。
大模型之战的表面是模型战,底层是工程战、基建战。2026 年以后,你听到的每一个"模型突破"背后,真正该关注的是:他们的 Infra 迭代了几轮。