三天前写了 DeepSeek-V4 的技术解读,后台收到最多的问题不是「V4 性能怎么样」,而是——
「V4 私有化部署到底要花多少钱?我们公司能不能自己搞?」
这才是企业最关心的事情。性能再强,用不起也白搭。
所以今天,我用 AWS H20 GPU 实例做了一次完整的 TCO 测算,把三个版本的部署成本掰开揉碎算一遍。结论可能比你想的便宜很多。

一、先搞清楚:三个模型,三个量级
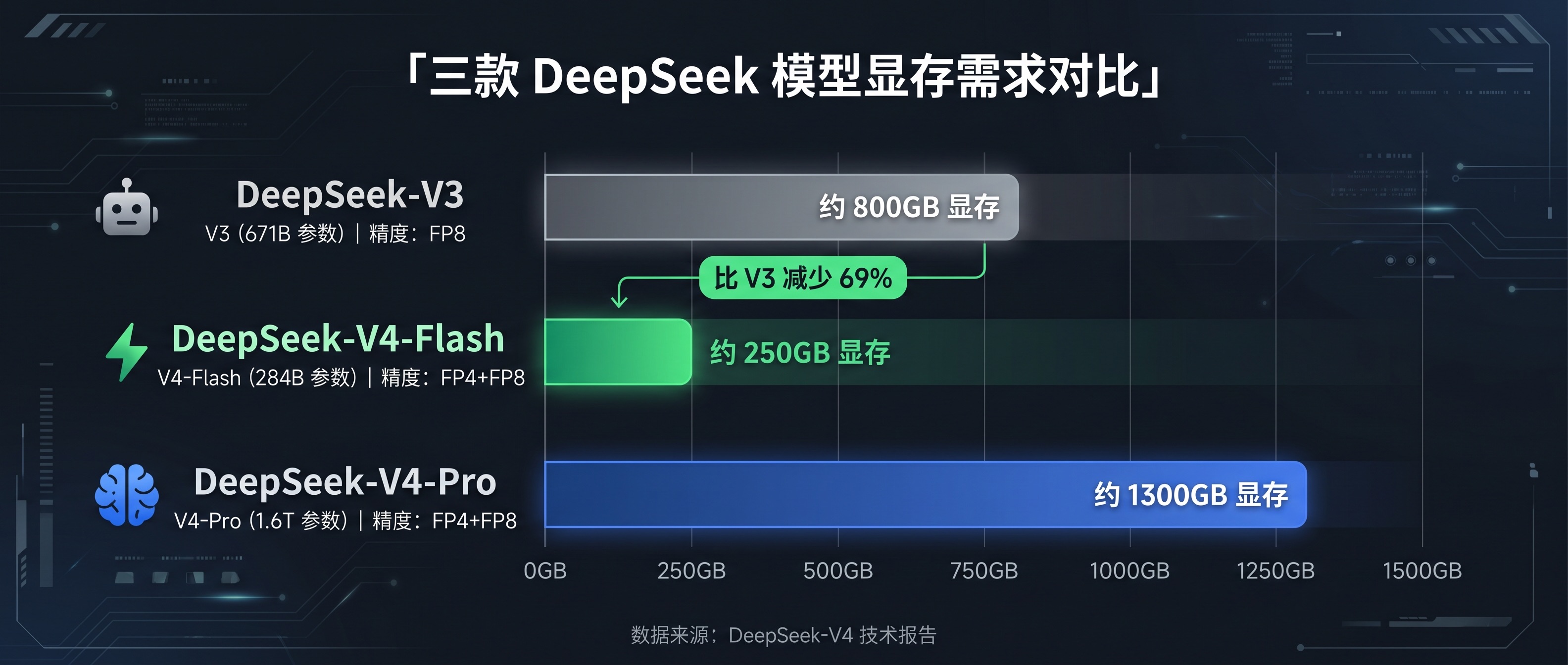
V4 系列现在有三个版本,显存需求差距巨大:
| 模型 | 总参数 | 激活参数 | 精度 | 显存需求 |
|---|---|---|---|---|
| V3(基线) | 671B | 37B | FP8 | ~800 GB |
| V4-Flash | 284B | 13B | FP4+FP8 混合 | ~250 GB |
| V4-Pro | 1.6T | 49B | FP4+FP8 混合 | ~1,300 GB |
关键数字来了:V4-Flash 的显存需求只有 V3 的 31%。 284B 参数量 + FP4 量化,把显存门槛从 800GB 直接拉到 250GB。这意味着什么?一台 8 卡 H20 实例(总显存 1128GB)就能装下。
V4-Pro 则是另一个故事——1.6T 参数需要约 1300GB 显存,至少 4 台 H20 才够。
二、硬件选型:为什么是 H20?
很多人第一反应是「上 H100 啊」。但现实是:H100 在中国大陆受出口管制,能稳定采购的高端 GPU 主要是 NVIDIA H20。
H20 单卡显存 141GB,8 卡实例总显存 1128GB。跑 V4-Flash 绰绰有余,跑 V4-Pro 需要 4 台。
vLLM/SGLang 已经适配 DeepSeek V4 架构,开箱即用。
| 模型 | GPU 配置 | H20 实例数 | 总显存 |
|---|---|---|---|
| V4-Flash(284B) | 8×H20 | 1 台 | 1,128 GB |
| V4-Pro(1.6T) | 8×H20 ×4 | 4 台 | 4,512 GB |
一句话:V4-Flash 是为 H20 量身定做的。 单节点部署、显存充裕、运维简单。V4-Pro 的多节点部署不仅贵,还涉及节点间通信延迟和运维复杂度——对大多数企业来说,不值得。
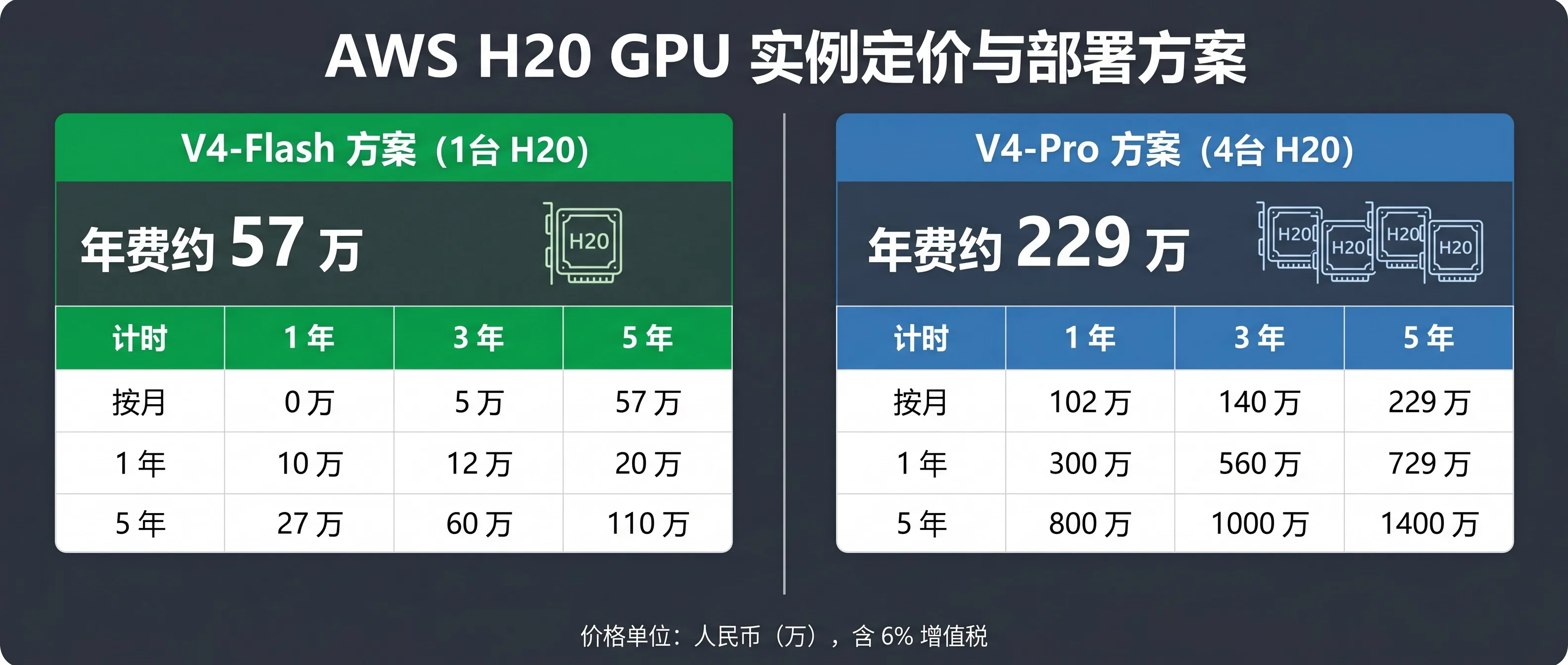
三、核心算账:H20 实例到底多少钱?
这是整篇文章最硬的部分。以下数据基于 AWS H20 实例 2026 年 4 月报价,单位人民币:
H20 实例定价(含税前后对比):
| 付费方式 | 单价(未税) | 折扣月费 | 含税月费(6%) |
|---|---|---|---|
| 按月 | ¥49,800/月 | ¥49,800 | ¥52,788 |
| 1 年合约 | ¥540,000/年 | ¥45,000 | ¥47,700 |
| 3 年合约 | ¥1,440,000/3年 | ¥40,000 | ¥42,400 |
| 5 年合约 | ¥2,130,000/5年 | ¥35,500 | ¥37,630 |
V4-Flash(1 台 H20)vs V4-Pro(4 台 H20)年成本对比:
| 维度 | V4-Flash | V4-Pro |
|---|---|---|
| 按月(未税) | ¥59.8 万/年 | ¥239.0 万/年 |
| 1 年合约 | ¥54.0 万 | ¥216.0 万 |
| 3 年合约(年均) | ¥48.0 万 | ¥192.1 万 |
| 5 年合约(年均) | ¥42.6 万 | ¥170.5 万 |
差距是 4 倍。 V4-Flash 一年合约 54 万(未税),V4-Pro 则需要 216 万。这还不算 DX 专线费用。
四、别忘了专线:DX 费用是隐藏成本
私有化部署不是买了 GPU 就完事——还需要一条稳定的 DX 专线连接 AWS 和你的企业网络。
| 供应商 | 免费带宽 | 超出计价 | 100M 月费参考 |
|---|---|---|---|
| 西云 | 20Mb/月 | ¥33/M/月 | ¥3,300/月 |
| 光环 | 20Mb/月 | ¥30/M/月 | ¥2,400/月 |
按 100M 带宽、光环供应商计算,DX 专线年费约 2.9 万。
五、年度 TCO 汇总:一张表看懂全局
把 GPU 实例、DX 专线加在一起,1 年合约 + 100M 带宽的年度 TCO:
| 项目 | V4-Flash(1 台) | V4-Pro(4 台) |
|---|---|---|
| H20 实例(含税) | ¥57.2 万 | ¥228.9 万 |
| DX 专线 100M(光环) | ¥2.9 万 | ¥2.9 万 |
| 年度 TCO | ~¥60 万 | ~¥232 万 |

60 万 vs 232 万,选择其实很明确。
注意:以上不含 DTO(数据传输费)、EBS 存储、运维人力等附加成本,实际落地会略高。但大头就是 GPU 实例,方向不会变。
六、我的建议:混合策略才是最优解
算完这笔账,结论很清晰:
V4-Flash 是私有化首选。 284B + FP4 量化,单台 H20 可部署,年 TCO 约 60 万。性能超越 V3,上下文 100 万 token,日常推理、内部工具调用、Agent 任务绑绑有余。
V4-Pro 用 API 弹性调用。 1.6T 参数的私有化代价是 4 台 H20 + 232 万年费,除非你是金融、安全等对数据主权有极端要求的行业,否则不划算。复杂推理任务直接调 V4-Pro API,按量付费,灵活又省钱。
推荐混合策略:
- 日常任务 → V4-Flash 私有化(核心数据不出网)
- 复杂推理 → 调用 V4-Pro API(弹性调用,按量计费)
- 实现「核心私有 + 弹性调用」的最优组合
这也是目前头部企业普遍采用的架构——把 80% 的日常推理留在本地,20% 的高端任务走云端 API。 既保数据安全,又不为算力过度买单。
写在最后
三天前我写 DeepSeek-V4 的时候说过一句话:开源追上闭源,不再是口号。
今天补上后半句:V4-Flash 让私有化部署的成本,也追上了可接受的范围。 60 万一年,对一家中型企业来说,就是两三个工程师的人力成本。换来的是一个 100 万 token 上下文、Agent 能力 TOP1 的私有大模型。
Zaokit 已成功融入 ToB 企业核心工作流,实现「信息检索 + 智能汇报」的一体化升级,大幅提升企业生产效率。目前,已有知名快消品行业企业正式采购并落地使用。感谢大家的支持,我们会持续打磨产品,创造更大的业务价值。
我一个人打造的 Zaokit AI 正在内测,2026年4月30日前1000名用户赠送价值150RMB的Pro计划,助力大家高效完成图文创作和PPT生成,唯一网站:zaokit.app。
别光看模型参数了。算清楚部署成本,选对混合策略——这才是企业用 AI 的正确姿势。