实战报告抢先看:本文附带三份AI量化系统生成的真实个股分析报告(NVDA、TSLA、AMZN),展示多智能体+分级调用的实际输出效果。👉 跳转到报告下载
上一篇AI量化交易深度分析发出后,后台收到最多的问题就是:
“你说分级调用能省60%成本,具体怎么分?用哪个模型?”
今天就把这个话题掰开了讲。
11个大模型,量化交易到底该怎么选?
一、先看全景:2026年大模型到底有多少选择?
截至2026年2月,全球主流大模型已经有11家厂商、20+款模型在跑。
你可能会问:这跟我做量化有什么关系?
关系大了。不同的模型就像不同岗位的员工——有的擅长搬砖(处理大量简单任务),有的擅长决策(复杂推理判断),有的性价比高(干得不错还便宜)。你的目标不是找到”最好的”,而是找到最合适的组合。
这就像组建一支足球队:你不会让11个梅西上场,你需要前锋、中场、后卫各司其职。
1.1 国际阵营:推理能力的天花板
| 厂商 | 最新模型 | 类型 | 关键数据 | 量化交易定位 |
|---|---|---|---|---|
| Anthropic | Claude Opus 4.6 / Sonnet 4.5 | 闭源 | 100万Token上下文,Terminal-Bench 65.4%(2026-02公开数据) | 决策大脑——最复杂的判断交给它 |
| OpenAI | GPT-5.3 Codex / o3 | 闭源 | GPT-5.3-Codex在Terminal-Bench 2.0达77.3%,API标注为”soon”;o3已提供API | 全能副手——什么都能干,干得都不错 |
| Gemini 3 Pro | 闭源 | 100万Token输入,6.4万Token输出 | 财报专家——200页年报一口气读完 | |
| Meta | Llama 4 Scout | 开源 | 1000万Token上下文 | 私有管家——部署在自己服务器上最安心 |
| xAI | Grok 4.1 | 闭源 | LMArena推理排名#1 | 推理悍将——数学推理突出 |
| Mistral | Large 3 | 开源 | 旗舰92%性能,仅15%价格 | 性价比之选——九成能力,一成半价格 |
1.2 中国阵营:成本与中文能力的双重优势
| 厂商 | 最新模型 | 类型 | 关键数据 | 量化交易定位 |
|---|---|---|---|---|
| DeepSeek | V3.2 / R1 | 开源 | 输入$0.27/百万Token(约为Claude的1/18) | 勤劳苦力——量大活糙不怕累 |
| 阿里云 | Qwen 3 | 开源 | 支持119种语言和方言 | 中文专家——A股新闻、政策解读 |
| 字节 | 豆包 | 闭源 | C端渗透率最高 | 工具调用能力强 |
| 百度 | 文心 5.0 | 闭源 | 搜索整合,实时信息获取 | 实时情报——联网搜索获取即时资讯 |
| 智谱/月之暗面 | GLM-4.7 / Kimi K2.5 | 开源/闭源 | 超长上下文 | 长文阅读器——超长研报、会议纪要 |
看到这里你可能已经懵了:这么多模型,到底该怎么选?
答案是:不选一个,而是搭配着用。
就像你不会只吃一道菜——主食管饱、蔬菜管健康、肉类管营养。模型也一样,各有分工。
二、先懂价格:2026年大模型到底多少钱?
在讲具体选型之前,你得先对价格有个概念。否则后面的讨论都是空中楼阁。
2.1 API按量付费:一张图看懂价格差异

2026年2月主流大模型API定价对比:价差可达60倍以上(按输出单价口径)
我把目前主流模型的API价格整理成一张表,单位统一换算成人民币(按1美元≈7.3元),方便你直接比较。注:不同厂商存在缓存价/批量价/分层价,以下统一按公开主价档口径横向对比。
| 模型 | 输入价格(每百万Token) | 输出价格(每百万Token) | 可用性说明 | 性能定位 |
|---|---|---|---|---|
| Claude Opus 4.6 | ¥36.5 | ¥182.5 | API可用 | 推理天花板 |
| GPT-5.3 Codex | - | - | 主要在Codex/ChatGPT可用,API待开放 | 全能型 |
| o3 | ¥14.6 | ¥58.4 | API可用 | 数学推理 |
| Gemini 3 Pro | ¥14.6 | ¥87.6 | API可用 | 长文档 |
| Claude Sonnet 4.5 | ¥21.9 | ¥109.5 | API可用 | 通用性价比 |
| Kimi K2.5 | ¥8 | ¥30 | API可用 | 长上下文 |
| DeepSeek-R1 | ¥4.0 | ¥16.0 | API可用 | 推理性价比 |
| Qwen 3 | ¥3.6 | ¥14.6 | API可用 | 中文专家 |
| DeepSeek-V3.2 | ¥2.0 | ¥3.0 | API可用 | 成本王者 |
一个直觉性的对比:按公开主价档,Claude Opus与DeepSeek-V3.2的单价差距约为输入18倍、输出61倍。落到真实任务里,成本差距通常在20-60倍,核心取决于输出长度控制(越“话多”越贵)。
数据口径说明(2026-02-08):Anthropic Pricing/Max、OpenAI GPT-5.3-Codex发布页、OpenAI o3模型页。后续若厂商调价,请以官方页面为准。
这就是分级调用的核心逻辑:简单的活儿用便宜的,关键的决策用最强的。
2.2 订阅制:固定月费”随便用”
除了按次付费,还有一种玩法——包月订阅。这对试水阶段的个人投资者特别友好:
| 订阅计划 | 月费 | 折合人民币 | 核心权益 | 适合谁 |
|---|---|---|---|---|
| Claude Max 5x | $100/月 | ~¥730 | 约为Pro配额5倍,含Extended Thinking | 轻度使用者 |
| Claude Max 20x | $200/月 | ~¥1,460 | 约为Pro配额20倍,最高优先级 | 认真做研究 |
| ChatGPT Pro | $200/月 | ~¥1,460 | GPT-5.3/o3高配额(非无限),深度研究模式,Sora视频 | 全能需求 |
| Google AI Ultra | $249.99/月 | ~¥1,825 | Gemini 3 Pro最高用量,100万上下文,25,000 AI积分 | 财报重度分析 |
我的建议:试水阶段(前3个月),花¥3,300/月订阅ChatGPT Pro + Google AI Ultra,手动+半自动分析,边学边调。等跑通了再切API按量付费。
订阅制是"学习期的最佳伴侣"——用固定成本获得顶级模型的充分体验,帮你在正式投入前搞清楚哪个模型真正好用。
三、量化交易的5个核心环节,各需要什么能力?
做AI量化不是只有一个AI在干活。回忆一下上篇文章讲的多智能体架构——每个Agent做的事情不一样,对模型的要求也不一样。
这就像医院的分诊制度:感冒发烧看全科,疑难杂症看专家。你不会因为手指划了个口子就挂专家号——浪费钱还浪费时间。
我把量化交易拆成5个环节,逐一分析。
环节一:新闻舆情分析——AI界的"实习生"就够了
做什么:每天抓取几百条财经新闻、社交媒体帖子,判断利好/利空/中性。
核心需求:中文理解能力、速度快、成本低
为什么不需要最强模型:这是”体力活”,每条新闻的分析逻辑相对简单——读懂内容、判断情绪、打个标签。就像让实习生做资料整理,不需要合伙人亲自上场。
| 推荐模型 | 原因 | 单次成本 |
|---|---|---|
| DeepSeek-V3.2 | 中文能力强,价格极低 | ~¥0.03 |
| Qwen 3 | 中文理解优秀,119种语言支持,开源可部署 | ~¥0.05 |
| GPT-4o | 速度快,多语言 | ~¥0.12 |
实测心得:我拿300条A股新闻做了对比测试。DeepSeek-V3.2用时约8分钟,成本不到¥10,情感分类准确率92%。同样的量用Claude Opus 4.6需要¥200+,准确率96%。多花20倍的钱,只换来4%的提升——在这个环节,性价比不划算。
环节二:财报深度解读——需要"资深分析师"
做什么:阅读完整年报(通常50-200页PDF),提取关键指标变化,分析管理层措辞的微妙变化。
核心需求:长上下文、推理能力、数字精准度
为什么需要好模型:财报分析不是简单的信息提取。CEO说"谨慎乐观"和"充满信心",背后的含义天差地别。你需要模型能读懂”言外之意”。
这里有一个真实案例:某上市公司2025年财报显示营收增长12%,看起来不错。但管理层讨论环节中,CFO三次使用了”审慎”一词,比前一年多了两次。传统量化只看到12%的增长,AI却捕捉到了管理层的谨慎信号——后来该公司果然在下一季度发布了利润预警。
| 推荐模型 | 原因 | 单次成本 |
|---|---|---|
| Gemini 3 Pro | 100万Token上下文,200页年报一次读完,不用切片 | ~¥3.0 |
| Claude Opus 4.6 | Terminal-Bench 65.4%(公开基准表现强),措辞分析精准 | ~¥7.5 |
| Kimi K2.5 | 长上下文能力突出,中文原生理解 | ~¥1.5 |
实测心得:一份120页的年报,Gemini 3 Pro可以一次性读入全文做分析,不用切片,这是它100万Token上下文窗口的巨大优势。Claude Opus 4.6拆成多段分析后综合,推理深度更好但耗时更长。建议:先用Gemini做初筛(成本¥3),对重点公司用Claude做深度分析(成本¥7.5)。一只股票的财报解读总成本控制在¥10以内。
环节三:多空辩论(Bull vs Bear)——需要"合伙人级别"
做什么:模拟投资委员会的正反方辩论——一个Agent找看多理由,一个找看空理由,互相挑战对方的逻辑漏洞。
核心需求:推理能力、逻辑严密性、批判性思维
为什么这是最关键的环节:这里的质量直接决定最终决策。如果看多的Agent逻辑不够严密,看空的Agent就发现不了漏洞。两个”水平不行”的Agent辩论,结论也不会好——就像让两个大学生辩论宏观经济,再怎么辩也很难得出深刻的结论。
 多空辩论架构:为什么这一步必须用最强模型?
多空辩论架构:为什么这一步必须用最强模型?
| 推荐模型 | 原因 | 单次成本 |
|---|---|---|
| Claude Opus 4.6 | 推理表现稳定(Terminal-Bench 65.4%),Finance Agent评分60.7% | ~¥7.5 |
| o3 | 数学推理顶级,Codeforces新纪录,定量分析精准 | ~¥2.3 |
| Grok 4.1 | LMArena推理排名#1 | ~¥6.0 |
实测心得:Claude Opus 4.6在辩论环节的表现最让我惊喜。它不仅能列出看多/看空的理由,还能主动指出对方论证中的薄弱环节——比如:”看多方提到的’行业景气度回升’依据的是2025年Q3数据,但Q4的PMI已经开始走弱,这个论据的时效性存疑。”这种批判性思维是其他模型比较弱的地方。
环节四:风险评估——数学能力定胜负
做什么:综合所有分析结果,评估仓位大小、止损点、风险收益比、VaR(在险价值)。
核心需求:数学能力、量化分析、保守偏好
风控为什么要单独拎出来:风控Agent的任务是”泼冷水”——别人说能赚,它要说可能亏多少。这个环节宁可过于保守,也不能过于激进。
| 推荐模型 | 原因 | 单次成本 |
|---|---|---|
| o3 | 数学推理最强,AIME满分,比o1减少20%错误 | ~¥2.3 |
| Claude Sonnet 4.5 | 性价比高,推理能力够用 | ~¥4.5 |
| DeepSeek-R1 | 推理链透明,32K Chain-of-Thought,成本低 | ~¥0.8 |
实测心得:风控计算对数学精度要求高,但逻辑复杂度适中(主要是公式计算)。Claude Sonnet 4.5在这个环节是性价比很高的选择——推理能力够用,价格显著低于Opus。DeepSeek-R1的优势在于它的32K推理链完全透明——你能看到它每一步的计算过程,出了问题容易排查。
环节五:综合决策——不能省钱的环节
做什么:汇总所有Agent的分析报告,做出最终的买/卖/持有决策,并生成可解释的投资报告。
核心需求:综合判断力、报告生成、逻辑自洽
| 推荐模型 | 原因 | 单次成本 |
|---|---|---|
| Claude Opus 4.6 | 综合推理+报告生成最强,GDPval-AA超GPT-5.2约144 Elo | ~¥7.5 |
| GPT-5.3 Codex | 全能选手,比前代快25% | 订阅配额内 |
实测心得:最终决策这个环节不能省钱。这里用便宜模型就像让实习生做最终拍板——风险太大。Claude Opus 4.6生成的决策报告逻辑链最清晰,每个结论都能追溯到具体的分析依据。而且它新增的Adaptive Thinking模式支持配置思考深度(low/medium/high/max),对于特别重要的决策可以开到max,让模型”想得更深”。
四、分级调用架构:省93%成本的秘密
把上面5个环节串起来,就是我推荐的三层金字塔架构:
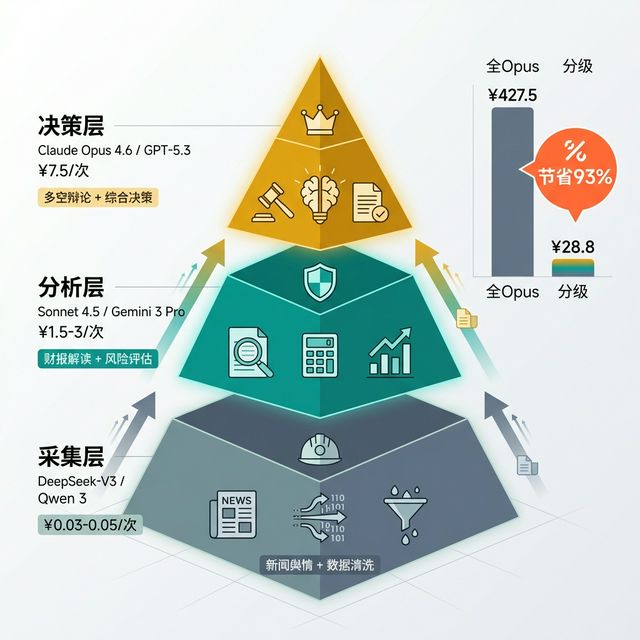 三层金字塔架构:不同环节用不同层级的模型,实现成本与质量的最优平衡
三层金字塔架构:不同环节用不同层级的模型,实现成本与质量的最优平衡
┌─────────────┐
│ 决策层 │ Claude Opus 4.6 / GPT-5.3
│ ¥7.5/次 │ 多空辩论 + 综合决策
└──────┬──────┘
┌─────┴─────┐
│ 分析层 │ Claude Sonnet 4.5 / Gemini 3 Pro
│ ¥3-4.5/次 │ 财报解读 + 风险评估
└─────┬─────┘
┌────────┴────────┐
│ 采集层 │ DeepSeek-V3 / Qwen 3
│ ¥0.03-0.05/次 │ 新闻舆情 + 数据清洗
└─────────────────┘
4.1 一只股票的完整分析成本
按一次完整的个股分析来算:
| 环节 | 模型 | 调用次数 | 单次成本 | 小计 |
|---|---|---|---|---|
| 新闻舆情 | DeepSeek-V3.2 | 50次 | ¥0.03 | ¥1.5 |
| 财报解读 | Gemini 3 Pro | 1次 | ¥3.0 | ¥3.0 |
| 多空辩论 | Claude Opus 4.6 | 2次 | ¥7.5 | ¥15.0 |
| 风险评估 | Claude Sonnet 4.5 | 1次 | ¥4.5 | ¥4.5 |
| 综合决策 | Claude Opus 4.6 | 1次 | ¥7.5 | ¥7.5 |
| 合计 | ¥31.5 |
4.2 对比:如果全部用最强模型
| 环节 | 模型 | 调用次数 | 单次成本 | 小计 |
|---|---|---|---|---|
| 新闻舆情 | Claude Opus 4.6 | 50次 | ¥7.5 | ¥375.0 |
| 财报解读 | Claude Opus 4.6 | 3次 | ¥7.5 | ¥22.5 |
| 多空辩论 | Claude Opus 4.6 | 2次 | ¥7.5 | ¥15.0 |
| 风险评估 | Claude Opus 4.6 | 1次 | ¥7.5 | ¥7.5 |
| 综合决策 | Claude Opus 4.6 | 1次 | ¥7.5 | ¥7.5 |
| 合计 | ¥427.5 |
分级调用节省了约93%的成本——从¥427.5降到¥31.5,主要省在新闻舆情这个”量大但简单”的环节。
4.3 月度成本估算
假设每天分析20只股票(覆盖自选股+行业龙头),每月22个交易日:
| 方案 | 月成本 | 年成本 | 适用人群 |
|---|---|---|---|
| 全部用Opus | ¥188,100 | ¥225.7万 | 土豪专属 |
| 分级调用(推荐) | ¥13,860 | ¥16.6万 | 认真做的个人/小团队 |
| 极致省钱版(全DeepSeek) | ¥2,640 | ¥3.2万 | 试水阶段 |
分级调用方案的月成本约¥1.4万,对于认真做量化的个人投资者来说,是可以承受的范围。
五、开源 vs 闭源:不是选择题,是搭配题
这是另一个高频问题。简短回答:不是非此即彼,而是各取所长。
5.1 一个直观的比喻
把模型选择想象成做饭:
- 闭源模型(Claude、GPT)= 米其林餐厅的大厨。味道最好,但每道菜都很贵。
- 开源模型(DeepSeek、Qwen、Llama)= 自己请的厨师。可以住在你家(私有部署),工资固定,但厨艺差一档。
你会怎么安排?日常吃饭让自家厨师做,重要宴请才去米其林。 模型选择的逻辑完全一样。
5.2 闭源模型的优势
- 能力上限高:Claude Opus 4.6在GDPval-AA等多项基准测试中位居前列,推理能力处于第一梯队
- 开箱即用:不需要部署和运维,API调用即可
- 持续更新:厂商会不断优化,你无需操心
适合场景:决策层、需要最强推理的环节
5.3 开源模型的优势
- 成本可控:DeepSeek V3.2的API价格仅为Claude Opus的1/18
- 数据安全:私有化部署,交易策略和持仓数据不出内网
- 可定制:可以针对金融场景微调——比如让模型更好地理解A股特有的”涨停板”“ST股”等概念
适合场景:采集层、数据清洗、对延迟不敏感的批量处理
5.4 私有化部署:什么时候值得做?
如果你对数据安全特别在意(比如不想让交易策略通过API传到外部),可以考虑私有化部署开源模型:
| 模型 | 最低硬件要求 | 部署难度 | 推荐场景 |
|---|---|---|---|
| DeepSeek-V3 (671B MoE) | 4x A100 80GB | 高 | 新闻分析、数据清洗 |
| Qwen 3 (72B) | 2x A100 80GB | 中 | 中文分析、舆情监控 |
| Llama 4 Scout | 4x A100 80GB | 高 | 多模态分析(图表识别) |
现实考虑:私有化部署的硬件成本不低。2x A100服务器月租约¥15,000-20,000。如果你的调用量不够大,直接用API反而更划算。经验法则:只有月API调用成本超过¥15,000时,私有化部署才有经济价值。
六、真实案例:Snowflake和量化教育圈怎么做的?
光讲理论不够,来看看行业里真实在做的事情。
6.1 Snowflake的AI量化研究管道
Snowflake在2026年公开了他们的AI量化研究管道架构:
- 财报电话会议情感分析:用LLM系统性处理上市公司的Earnings Call记录,自动提取管理层情绪变化
- 事件驱动研究:实时抓取新闻和公告,自动判断对特定股票的影响方向和程度
- ML预测选股:结合传统ML模型和LLM的非结构化数据处理能力
他们的关键发现:在财报文本分析这个环节,LLM比传统NLP方法的准确率提高了23%——因为LLM能理解上下文语境,而不仅仅是关键词匹配。
6.2 Quantopian 2026年春季课程
全球最知名的量化教育平台Quantopian,在2026年春季开设了一门14周的专题课程:“Applications of LLMs and AI in Quantitative Finance”。课程涵盖:
- 金融领域LLM和Embeddings的应用
- 用聚类算法做市场机制检测(Regime Detection)
- RAG(检索增强生成)在SEC文件和新闻分析中的应用
- LLM Agent在投资研究中的多智能体协作
- 交易推荐和投资组合优化
为什么这很重要? 当Quantopian这样的权威机构开始系统性地教授LLM在量化中的应用,说明这条路径已经从”实验性探索”进入了”工程化实践”阶段。
6.3 Azilen Technologies的选型评测
Azilen Technologies在2026年1月发布了一份金融领域LLM选型指南,他们的实测结论与我的经验高度一致:
- 合规报告生成:Claude系列在多文档分析方面表现最强
- 市场情绪分析:Gemini在处理大量非结构化数据时效率最高
- 异常检测叙述:GPT系列在生成可解释性报告方面表现最佳
多家机构的独立验证指向同一个结论:没有"万能模型",分级搭配才是正解。
七、AWS上跑AI量化的成本拆解
很多读者问:在云上跑整套系统要花多少钱?这里拿AWS来算一笔账。
7.1 基础架构成本
| 组件 | AWS服务 | 规格 | 月成本 |
|---|---|---|---|
| 策略服务器 | EC2 | t3.xlarge (4vCPU, 16GB) | ~¥450 |
| 数据库 | RDS PostgreSQL | db.t3.medium | ~¥350 |
| 数据缓存 | ElastiCache Redis | cache.t3.small | ~¥180 |
| 定时任务 | Lambda | 每日触发 | ~¥5 |
| 消息队列 | SQS | 标准队列 | ~¥10 |
| 监控 | CloudWatch | 基础监控 | ~¥30 |
| 基础设施小计 | ~¥1,025 |
7.2 完整月度成本
| 项目 | 月成本 |
|---|---|
| AWS基础设施 | ¥1,025 |
| 大模型API(分级调用) | ¥13,860 |
| 数据源(Tushare Pro等) | ¥200 |
| 总计 | ~¥15,100 |
年化成本约¥18.1万。如果按¥500万本金计算,运营成本占本金的3.6%——也就是说,策略年化收益率需要跑赢3.6%才能覆盖成本。考虑到目标是年化12%以上,成本占比是可接受的。
八、模型选型速查表
最后给一张决策速查表,方便你根据自己的情况快速选择:
8.1 按预算选
| 月预算 | 推荐方案 | 预期效果 |
|---|---|---|
| < ¥3,000 | 全部用DeepSeek + Qwen | 能跑通流程,决策质量一般 |
| ¥3,000-15,000 | 三层分级(推荐) | 最佳性价比,决策质量有保障 |
| > ¥15,000 | 分级 + 私有化部署 | 数据安全 + 成本优化 |
8.2 按场景选
| 如果你是… | 推荐方案 |
|---|---|
| 个人投资者,试水阶段 | 订阅ChatGPT Pro + Google AI Ultra,月成本¥3,300以内 |
| 个人投资者,认真做 | 三层分级API调用,月成本¥1.4万 |
| 小型私募/工作室 | 分级 + Llama 4私有化,注重数据安全 |
| 机构投资者 | Claude/GPT全栈 + 私有化,不差钱差质量 |
8.3 一句话总结每个模型
| 模型 | 一句话定位 | 核心数据支撑 |
|---|---|---|
| Claude Opus 4.6 | 决策大脑——最复杂的判断交给它 | Terminal-Bench 65.4%,Finance Agent 60.7% |
| GPT-5.3 Codex | 全能副手——什么都能干,干得都不错 | 比前代快25%,Terminal-Bench 2.0达77.3%,API状态为”soon” |
| Gemini 3 Pro | 财报专家——200页年报一口气读完 | 100万Token输入,上下文缓存低至$0.20/M |
| o3 | 数学天才——风控计算、定量分析 | AIME满分,比o1减少20%错误,API价格$2/$8(每百万Token) |
| DeepSeek-V3.2 | 勤劳苦力——量大活糙不怕累,成本极低 | 输入仅$0.27/百万Token |
| Qwen 3 | 中文专家——A股新闻、政策解读 | 119种语言和方言支持 |
| DeepSeek-R1 | 透明推理——每一步计算过程都看得见 | 32K Chain-of-Thought推理链 |
| Llama 4 Scout | 私有管家——部署在自己服务器上最安心 | 1000万Token上下文 |
| Kimi K2.5 | 长文阅读器——超长研报、会议纪要 | 中文原生长上下文 |
| Mistral Large 3 | 性价比之选——92%的能力,15%的价格 | 开源可部署 |
九、下一步:动手验证
说到底,模型选型不是纸上谈兵的事。上篇文章提到的三阶段验证法,第一阶段(策略验证)的核心任务之一就是确定你的最优模型组合。
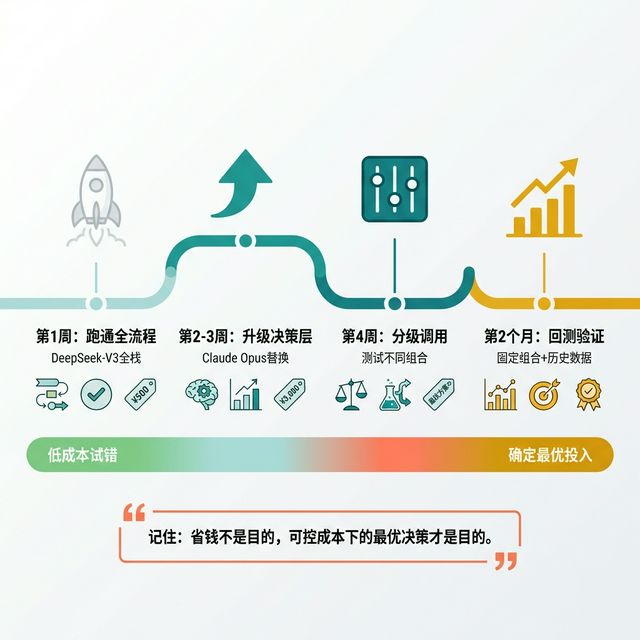 四周验证路线:从跑通流程到确定最优组合
四周验证路线:从跑通流程到确定最优组合
我的建议:
- 第1周:用DeepSeek-V3.2跑通全流程,确认管道没问题
- 第2-3周:把决策层换成Claude Opus 4.6,对比输出质量差异
- 第4周:加入分级调用,测试不同组合的成本和效果
- 第2个月:固定模型组合,开始跑回测
记住:省钱不是目的,在可控成本下获得最优决策质量才是目的。
相关阅读
AI量化系列
- AI量化交易深度分析:当AI学会”思考”股票 - 概念与架构
- 用OpenClaw做A股量化?我试了试 - 实战探索
- OpenClaw之父的AI Agent实战手册 - 与AI协作的方法论
大模型系列
- 通用AGI工具已经到来 - Claude Code深度分析
- 你觉得AI不行?也许是你的’使用姿势’还停在2023年 - AI使用姿势演进
延伸资源
- TradingAgents-CN - A股多Agent量化框架(GitHub)
联系方式
如果你也在搭建AI量化系统,特别想交流:
- 你用的是什么模型组合?
- 分级调用的实际效果如何?
-
开源模型在金融场景的表现怎么样?
- 邮箱:[email protected]
- 微信:winnielove2020
- 博客:https://junxinzhang.com
附录:实战分析报告
本文首发于2026年2月8日,以下三份报告为2026年2月8日补充更新:由AI多智能体量化系统(分级调用架构)生成,完整展示了新闻舆情分析、财报解读、多空辩论、风险评估和综合决策的全流程输出。你可以直接点击预览或下载:
| 股票 | 报告 | 说明 |
|---|---|---|
| NVDA(英伟达) | 📄 查看报告 | AI芯片龙头,典型的高波动成长股分析。报告覆盖了英伟达最新财报数据、AI算力需求趋势、以及与AMD/Intel的竞争格局分析。 |
| TSLA(特斯拉) | 📄 查看报告 | 多空分歧最大的标的,辩论环节最精彩。报告涵盖FSD自动驾驶进展、能源业务增长、产能扩张计划,以及估值争议的正反方深度辩论。 |
| AMZN(亚马逊) | 📄 查看报告 | 云计算+电商双引擎,财报解读的典型案例。报告重点分析了AWS云业务增速、广告业务突破、以及零售利润率改善的可持续性。 |
有效期说明:三份报告的数据采集和分析均基于2026年2月8日的市场信息,包括当日及此前的新闻舆情、最新季度财报、分析师评级等。报告中的买入/卖出/持有建议仅反映该时点的市场状况,不构成投资建议。市场瞬息万变,请结合最新信息做出自己的判断。
阅读建议:重点关注报告中的「多空辩论」和「综合决策」部分——这两个环节使用了Claude Opus 4.6,是分级调用中”决策层”的实际表现。对比「新闻舆情」部分(DeepSeek-V3.2生成),你能直观感受到不同层级模型的输出差异。
下一篇预告:AI量化交易实战(三)——多智能体Prompt工程:如何让Bull和Bear Agent真正”吵”起来。
关注我,不错过后续实战分享。