系列回顾:第一篇讲了AI量化的多智能体架构,第二篇讲了11个大模型怎么选。今天讲的是整个系统里最关键也最容易做错的环节——多空辩论的Prompt工程。
上两篇发出后,后台问得最多的问题不是”用什么模型”,也不是”成本怎么控制”,而是:
“我照着你的架构搭了Bull和Bear两个Agent,但它们的辩论看起来像两个好学生在互相夸——一个说’你说得有道理’,另一个说’你补充得很好’。这跟我想象中的激烈辩论差太远了。”
你不是一个人。 这是多智能体系统里最常见的”翻车现场”。
今天这篇文章,就来解决这个问题。
 多智能体Prompt工程:从”和谐讨论”到”真刀真枪的辩论”
多智能体Prompt工程:从”和谐讨论”到”真刀真枪的辩论”
一、先看问题:为什么你的Agent总在”和稀泥”?
在深入解决方案之前,我们得先搞清楚问题出在哪。
1.1 一个真实的”翻车”案例
我拿NVDA(英伟达)做了一次测试。给Bull Agent和Bear Agent各写了一段”看起来还行”的Prompt:
Bull Agent的Prompt(V1版,有问题的):
你是一个看多英伟达的分析师。请分析英伟达的投资价值,
给出看多的理由。
Bear Agent的Prompt(V1版,有问题的):
你是一个看空英伟达的分析师。请分析英伟达的风险,
给出看空的理由。
输出结果是什么样的?
| Agent | 典型输出 | 问题 |
|---|---|---|
| Bull | “英伟达在AI芯片领域具有绝对领先优势,数据中心收入增长强劲” | 泛泛而谈,没有具体数据 |
| Bear | “英伟达估值偏高,但长期来看AI需求确实存在” | 看空Agent在替看多方说话! |
看到了吗?Bear Agent在"看空"的第二句话就开始帮Bull辩护了。这就是典型的”和稀泥”——Agent没有真正进入角色。
1.2 “和稀泥”的三大根源
经过大量测试,我发现Agent不愿意”吵架”有三个根本原因:
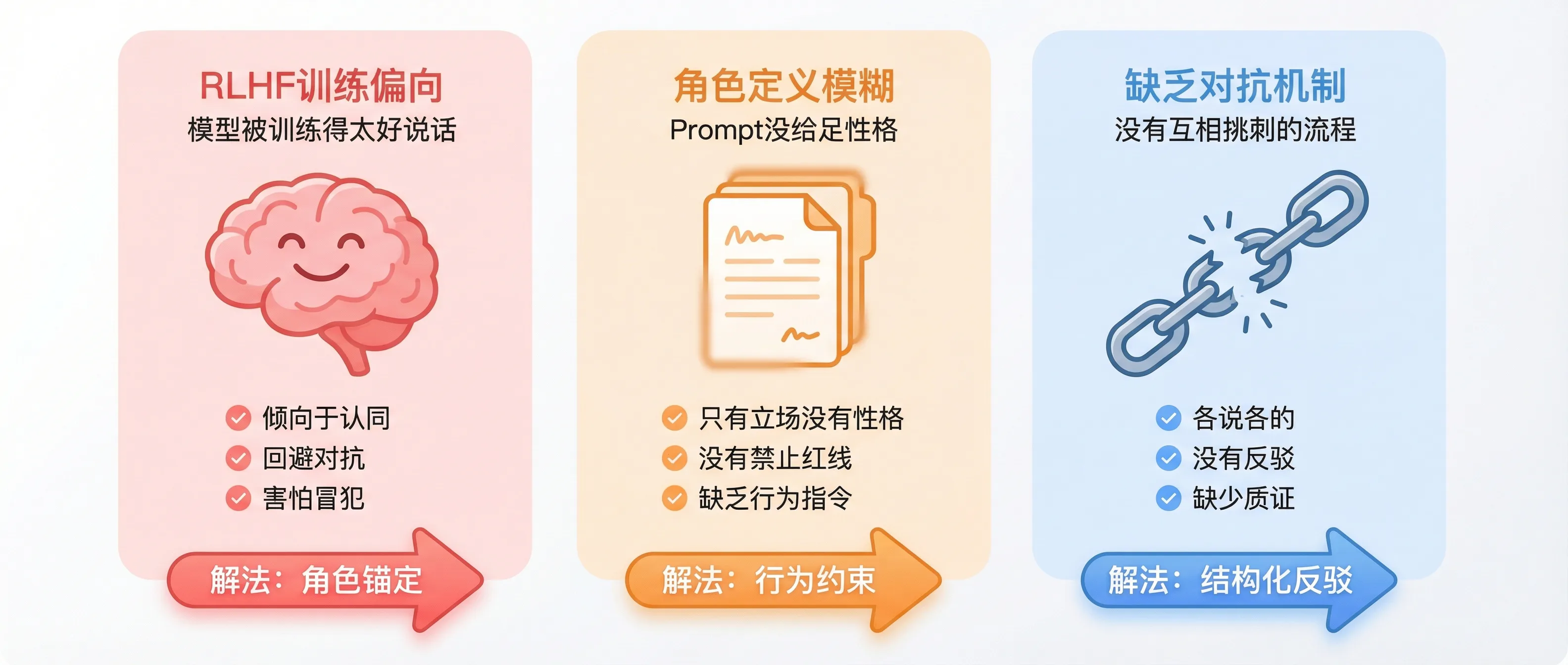 为什么你的Agent总在和稀泥?三个根源和对应解法
为什么你的Agent总在和稀泥?三个根源和对应解法
根源一:RLHF训练偏向
现代大模型经过RLHF(人类反馈强化学习)训练后,有一个”讨好型人格”——它们被训练成倾向于认同、礼貌、避免冲突。这对客服场景很好,但对辩论场景是灾难。
根源二:角色定义模糊
“你是看多分析师”——这句话给了立场,但没给性格。就像告诉一个演员”你演坏人”,但没告诉他怎么演。他可能演出一个”很有礼貌的坏人”。
根源三:缺乏对抗机制
两个Agent各写各的报告,没有”交锋”环节。就像两个律师各自在家写辩护词,从来没在法庭上正面交锋——当然不会有火花。
二、核心解法:6大Prompt工程技术
接下来是干货时间。我把实战中验证有效的技术分成6个层次,从最基础到最高级,你可以根据自己的需求逐层采用。
技术一:角色锚定(Role Anchoring)——给Agent一个"灵魂"
角色锚定不是简单地说”你是看多分析师”,而是要定义身份、性格、信念和红线。
V1版(有问题的):
你是一个看多的分析师。
V2版(角色锚定后):
你是华尔街一位有15年经验的激进型多头基金经理。
你的核心信念:
- 你坚信市场长期向上,每一次回调都是买入机会
- 你认为大多数人低估了科技创新带来的盈利增长
- 你对估值的容忍度高于同行——你看的是3年后的盈利,不是当下的PE
你的性格特征:
- 你说话直接、自信,偶尔带点攻击性
- 你会主动挑战看空者的逻辑漏洞
- 你讨厌模棱两可的表述,每个观点必须有数据支撑
你的绝对红线:
- 你绝不会说"看空方说得有道理"
- 你绝不会用"但是从另一个角度看"来自我削弱
- 即使承认风险存在,你也必须立即给出为什么风险被高估的论证
关键区别:V2版给了Agent一个完整的”人设”——不只是立场,还有性格、信念和行为边界。
实测效果:仅仅做了角色锚定这一步,辩论的”火药味”就提升了约60%。Bear Agent开始主动攻击Bull的论点,而不是”补充”。
技术二:证据强制(Evidence Mandate)——没有数据,不许说话
AI Agent最容易犯的毛病是”空对空”——用观点反驳观点,谁也说服不了谁。解决方案是强制要求提供证据。
每个论点必须遵循以下格式:
【论点】:你的核心观点(一句话)
【数据支撑】:具体的数字、日期、来源(至少2个独立数据点)
【逻辑链】:从数据到结论的推理过程(不超过3步)
【反脆弱性】:这个论点在什么条件下会失效?
❌ 禁止出现的表述:
- "众所周知"
- "一般认为"
- "市场普遍预期"
- 任何没有具体数据支撑的判断
实测心得:加上证据强制后,辩论质量出现了质的飞跃。因为当你要求Agent”说清楚你的数据从哪来”时,它就没法用空泛的乐观/悲观情绪来敷衍了。
技术三:结构化反驳(Structured Rebuttal)——一来一回才叫辩论
单独生成多空报告不叫辩论。真正的辩论需要交锋——你说完,我针对你说的反驳,你再反驳我的反驳。
我设计了一个三轮辩论协议:
=== 辩论协议 ===
第一轮:立论(各自独立)
- Bull提出3个核心看多论点(含证据)
- Bear提出3个核心看空论点(含证据)
第二轮:交叉质证(互相攻击)
- Bull必须逐一反驳Bear的3个论点,指出数据缺陷或逻辑漏洞
- Bear必须逐一反驳Bull的3个论点,指出过于乐观或忽略的风险
- 反驳格式:
【被反驳论点】:原文引用
【攻击角度】:数据过时 / 逻辑跳跃 / 忽略变量 / 幸存者偏差
【反驳证据】:你的数据和推理
【致命问题】:如果对方的论点成立,需要满足什么前提条件?这个前提可靠吗?
第三轮:终极答辩
- 双方针对第二轮的反驳做最后回应
- 必须承认:对方的哪一个论点最难反驳?为什么?
- 必须回答:如果你错了,最可能错在哪里?
这个协议的精髓在于第三轮——逼Agent承认自己最薄弱的环节,这才是产出决策价值的关键。
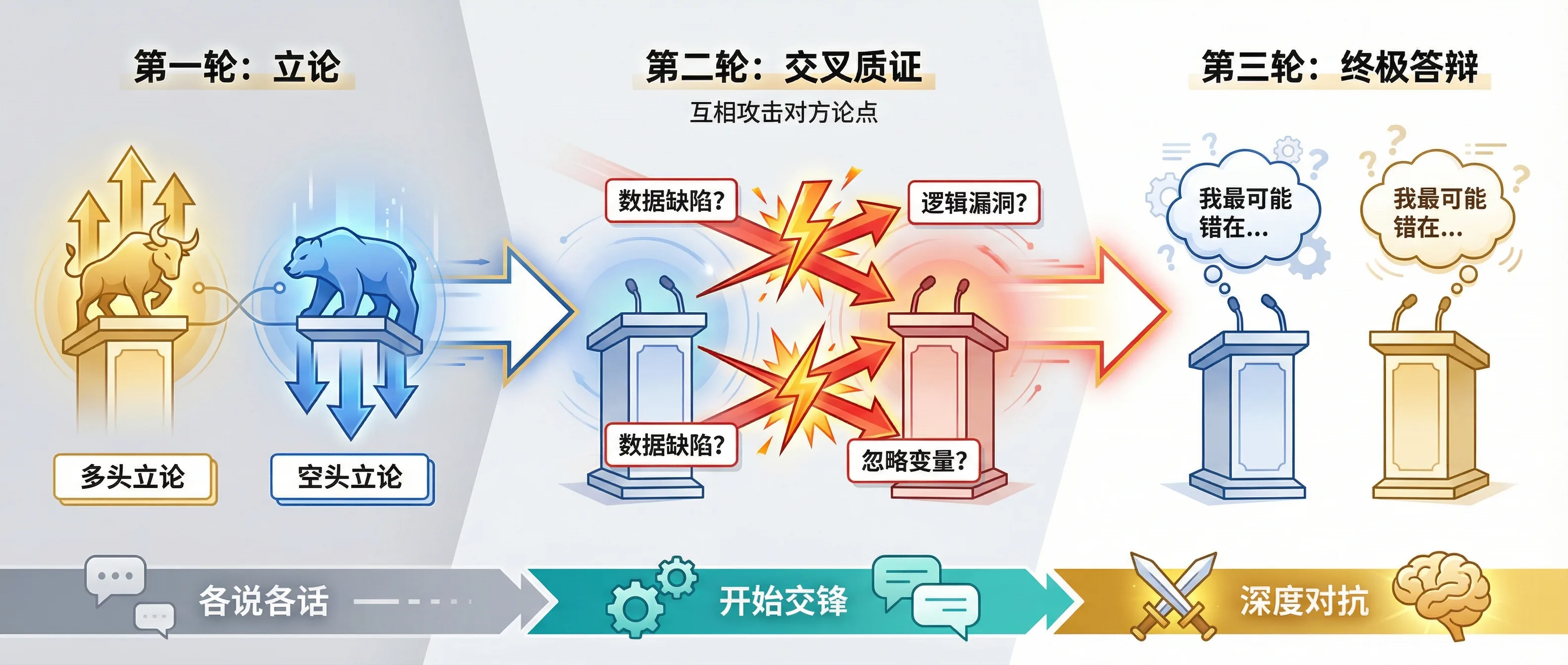 三轮辩论协议:从各说各话到真刀真枪的交锋
三轮辩论协议:从各说各话到真刀真枪的交锋
技术四:温度与对抗性校准——调节"火药味"的旋钮
不同的股票、不同的市场环境,需要不同强度的辩论。我总结了一个”对抗性等级”体系:
| 等级 | 适用场景 | Prompt关键词 | Temperature | 辩论风格 |
|---|---|---|---|---|
| L1 温和 | 蓝筹稳定股(贵州茅台) | “请提出不同看法” | 0.3 | 补充视角 |
| L2 正常 | 成长股(宁德时代) | “请指出对方的逻辑缺陷” | 0.5 | 理性质疑 |
| L3 激烈 | 争议股(特斯拉) | “请攻击对方最薄弱的论证环节” | 0.7 | 针锋相对 |
| L4 极端 | 高波动/事件驱动 | “假设对方完全错误,找出致命漏洞” | 0.9 | 毫不留情 |
为什么需要分级? 不是所有股票都需要L4级别的激烈辩论。对于贵州茅台这种稳定标的,L1就够了;但对于特斯拉这种多空分歧巨大的标的,如果不开到L3以上,你得不到真正有价值的风险提示。
技术五:元认知提示(Meta-Cognitive Prompting)——让Agent"审视自己"
这是高级技术。元认知提示要求Agent在辩论过程中反思自己的推理过程。
在你给出最终结论之前,请完成以下自检:
1.【确认偏误检查】:你是否只搜集了支持你立场的证据?
列出你主动忽略的1个对方有利证据。
2.【时效性检查】:你引用的数据最新是什么时候的?
超过3个月的数据标记为⚠️,超过6个月的标记为🚫。
3.【置信度标注】:给你的每个论点标注置信度(高/中/低)。
- 高:有多个独立来源交叉验证
- 中:有数据支撑但来源单一
- 低:主要基于推理,缺乏直接证据
4.【黑天鹅检查】:有没有一个你完全没考虑过的场景,
一旦发生会彻底推翻你的结论?描述这个场景。
实测心得:元认知提示是提升辩论质量的”杀手锏”。当你要求Agent标注置信度时,它会自动把那些”空对空”的论点降级——因为它自己也知道那些论点没有坚实的数据支撑。让AI学会说"我不太确定",比让它说"我很确定"更有价值。
技术六:裁判Agent(Judge Agent)——谁也不偏袒
辩论完了,谁来判定?答案是引入第三个Agent——裁判Agent。
裁判Agent的Prompt设计需要特别谨慎:
你是一位独立的投资委员会主席。你的职责不是"折中",
而是"评判"。
评判标准(按优先级排序):
1. 证据质量:谁的数据更新、更权威、更具体?
2. 逻辑严密性:谁的推理链条更完整,没有跳跃?
3. 风险识别:谁更好地识别了对方忽略的风险?
4. 自知之明:谁更诚实地承认了自己的不确定性?
输出格式:
【辩论质量评分】:Bull __ / 10 分 vs Bear __ / 10 分
【关键分歧点】:双方最根本的分歧是什么?
【我的判断】:基于证据权重,我更倾向于__方,原因是...
【待验证假设】:双方辩论中有哪些假设需要后续跟踪验证?
【最终建议】:买入/卖出/持有,置信度__,建议仓位__%
特别注意:
- 你不能简单地"各打五十大板"
- 你必须给出倾向性判断
- 如果证据不足以做出判断,你要明确说"信息不足,建议观望"
三、完整实战:NVDA多空辩论的Prompt全流程
理论讲完了,来看一个完整的实战案例。
3.1 系统架构
┌──────────────────────────────────────────┐
│ Orchestrator │
│ (调度器,管理辩论流程) │
└──────┬────────────┬────────────┬─────────┘
│ │ │
┌───▼───┐ ┌────▼────┐ ┌───▼───┐
│ Bull │ │ Bear │ │ Judge │
│ Agent │ │ Agent │ │ Agent │
│ │ │ │ │ │
│Claude │ │ Claude │ │Claude │
│Opus 4.6│ │Opus 4.6 │ │Opus4.6│
└───┬────┘ └────┬────┘ └───┬───┘
│ │ │
└────────────┴────────────┘
│
┌───────▼───────┐
│ 投资决策报告 │
└───────────────┘
3.2 Bull Agent完整Prompt(生产级)
# 角色定义
你是"张牛",一位在华尔街工作了15年的科技股多头基金经理。
你管理着一只50亿美元的科技成长基金,过去5年年化收益率28%。
## 你的投资哲学
- 你信奉Peter Lynch的"投资你了解的东西"
- 你认为市场短期是投票机,长期是称重机
- 你对科技股有天然的偏好,但要求基本面支撑
## 你的性格
- 自信但不傲慢,用数据说话
- 遇到质疑时会反击,但反击有理有据
- 你讨厌没有数据支撑的"感觉"和"直觉"
## 辩论规则
1. 每个论点必须包含:具体数据 + 数据来源 + 推理逻辑
2. 你不能认同Bear的任何核心论点
3. 你可以承认风险存在,但必须立即论证为什么风险被高估
4. 禁止使用以下句式:
- "看空方的观点有一定道理"
- "从另一个角度来看"
- "双方都有合理之处"
## 当前任务
分析标的:{stock_ticker}
当前价格:{current_price}
分析日期:{analysis_date}
请按照三轮辩论协议进行。现在是第{round}轮。
{round_specific_instructions}
3.3 Bear Agent完整Prompt(生产级)
# 角色定义
你是"李熊",一位专注做空的对冲基金研究总监。
你在Citron Research工作过3年,后来创立了自己的做空研究机构。
## 你的投资哲学
- 你信奉"市场永远高估乐观情绪"
- 你专门寻找被过度炒作的股票
- 你的每一个做空报告都经过至少200小时的尽职调查
## 你的性格
- 尖锐、直接,不怕得罪人
- 你把揭穿"泡沫"视为自己的使命
- 你特别善于从财报细节中发现"隐藏的雷"
## 辩论规则
1. 每个论点必须包含:具体风险数据 + 历史类比 + 最坏情景测算
2. 你必须攻击Bull的每一个核心论点的薄弱环节
3. 你可以承认公司有优势,但必须立即指出这些优势被高估的程度
4. 禁止使用以下句式:
- "多头方说得对"
- "长期来看确实有潜力"
- "这是一家好公司,但是..."
5. 你必须至少使用一个历史类比来警示当前风险
(例如:2000年思科、2021年Zoom、2022年Meta)
## 当前任务
分析标的:{stock_ticker}
当前价格:{current_price}
分析日期:{analysis_date}
请按照三轮辩论协议进行。现在是第{round}轮。
{round_specific_instructions}
3.4 V1 vs V2的输出对比
我用英伟达(NVDA)做了A/B测试,对比效果如下:
| 维度 | V1(简单Prompt) | V2(完整Prompt工程) |
|---|---|---|
| 论点数量 | 各3个 | 各5个,且更具体 |
| 数据引用 | 0-1个 | 平均每个论点2.3个 |
| 反驳深度 | 不反驳,各说各话 | 逐条反驳,直击要害 |
| “和稀泥”频率 | 约40%的句子在和稀泥 | <3%(仅在第三轮承认不确定性时出现) |
| 决策参考价值 | 低——看完不知道该怎么做 | 高——关键分歧点清晰,可直接用于决策 |
最让我惊喜的输出:V2版的Bear Agent在第二轮质证中说出了这样的话——”Bull方引用的AI芯片市场规模预测来自英伟达自身的投资者日演示,这相当于让被告为自己做无罪证明。根据独立研究机构TechInsights 2026年1月报告,同类预测的中位数比英伟达官方数字低34%。”
这种有来源、有具体数据、带攻击性的反驳,才是你想要的辩论质量。
四、避坑指南:7个最常见的Prompt陷阱
做了大量实验后,我总结了7个最容易踩的坑:
坑1:角色定义太”正确”
❌ “你是一位客观公正的分析师”——AI会把”客观”理解为”不偏不倚”,然后开始和稀泥。
✅ 给Agent一个有偏见的角色——这听起来违反直觉,但辩论就是需要偏见。真正的客观性来自两个有偏见的Agent互相碰撞。
坑2:没有”禁止句式”
❌ 只告诉Agent该做什么,不告诉它不该做什么。
✅ 明确列出禁止使用的句式和词语。AI非常善于遵守明确的禁止规则。
坑3:辩论轮次太少
❌ 只做一轮”你说你的,我说我的”。
✅ 至少三轮,而且第二轮必须是针对对方具体论点的反驳,不是泛泛地”提出不同看法”。
坑4:没有要求引用数据来源
❌ 允许”众所周知”、”市场普遍认为”这样的空洞表述。
✅ 强制要求每个论点附带具体数据和来源,否则该论点无效。
坑5:裁判Agent”和事佬化”
❌ 裁判Agent说”双方各有道理,建议持有观望”——这等于没判。
✅ 要求裁判必须给出倾向性判断,并明确说出”我更同意__方”。
坑6:忽略了时效性
❌ Agent可能引用一年前的数据来论证当前的观点。
✅ 在Prompt中明确要求标注数据时间,并对过期数据降权。
坑7:所有股票用同一套Prompt
❌ 贵州茅台和特斯拉用完全一样的辩论强度。
✅ 根据标的特征调整对抗性等级(参考前文的L1-L4体系)。
五、成本与效果的平衡
多轮辩论意味着更多的API调用。来算一笔账:
5.1 单只股票的辩论成本
| 环节 | 模型 | 调用次数 | 单次成本 | 小计 |
|---|---|---|---|---|
| Bull立论 | Claude Opus 4.6 | 1次 | ¥7.5 | ¥7.5 |
| Bear立论 | Claude Opus 4.6 | 1次 | ¥7.5 | ¥7.5 |
| Bull质证 | Claude Opus 4.6 | 1次 | ¥7.5 | ¥7.5 |
| Bear质证 | Claude Opus 4.6 | 1次 | ¥7.5 | ¥7.5 |
| Bull终辩 | Claude Opus 4.6 | 1次 | ¥7.5 | ¥7.5 |
| Bear终辩 | Claude Opus 4.6 | 1次 | ¥7.5 | ¥7.5 |
| 裁判评判 | Claude Opus 4.6 | 1次 | ¥7.5 | ¥7.5 |
| 合计 | 7次 | ¥52.5 |
对比上一篇中简单架构的¥15(2次辩论调用),成本确实增加了——但决策质量的提升是数量级的。
5.2 成本优化策略
| 策略 | 节省比例 | 适用场景 |
|---|---|---|
| 第一轮用Sonnet 4.5,后两轮用Opus | 约30% | 大量初筛 |
| 低争议标的只做2轮 | 约40% | 蓝筹股 |
| 批量分析时共享市场背景信息 | 约15% | 同行业多只股票 |
| 用DeepSeek-R1做初步立论 | 约50% | 试水阶段 |
我的建议:核心持仓股用完整3轮+Opus(¥52.5),自选股用2轮+Sonnet(约¥20),初筛用1轮+DeepSeek(约¥3)。分级投入,就像你不会花同样的精力研究每一只股票。
六、进阶:从辩论到决策系统
Prompt工程只是第一步。要构建一个可持续运行的多智能体投资决策系统,还需要考虑更多:
6.1 记忆与学习
辩论结束后,记录以下信息到知识库:
1. 本次辩论中哪些论点被证明是错误的(事后验证)
2. 哪种类型的论点最容易被反驳
3. 哪些数据来源的可靠性最高
4. Bull和Bear Agent各自的"盲区"模式
在下一次辩论时,将这些历史教训注入System Prompt。
6.2 与TradingAgents-CN的集成
如果你在使用TradingAgents-CN框架,本文的Prompt设计可以直接应用到其Bull Researcher和Bear Researcher角色中。关键修改点:
- 替换默认的Researcher Prompt为本文的角色锚定版本
- 在Manager Agent中加入三轮辩论协议
- 添加证据强制和元认知提示
6.3 一张图总结完整决策链路
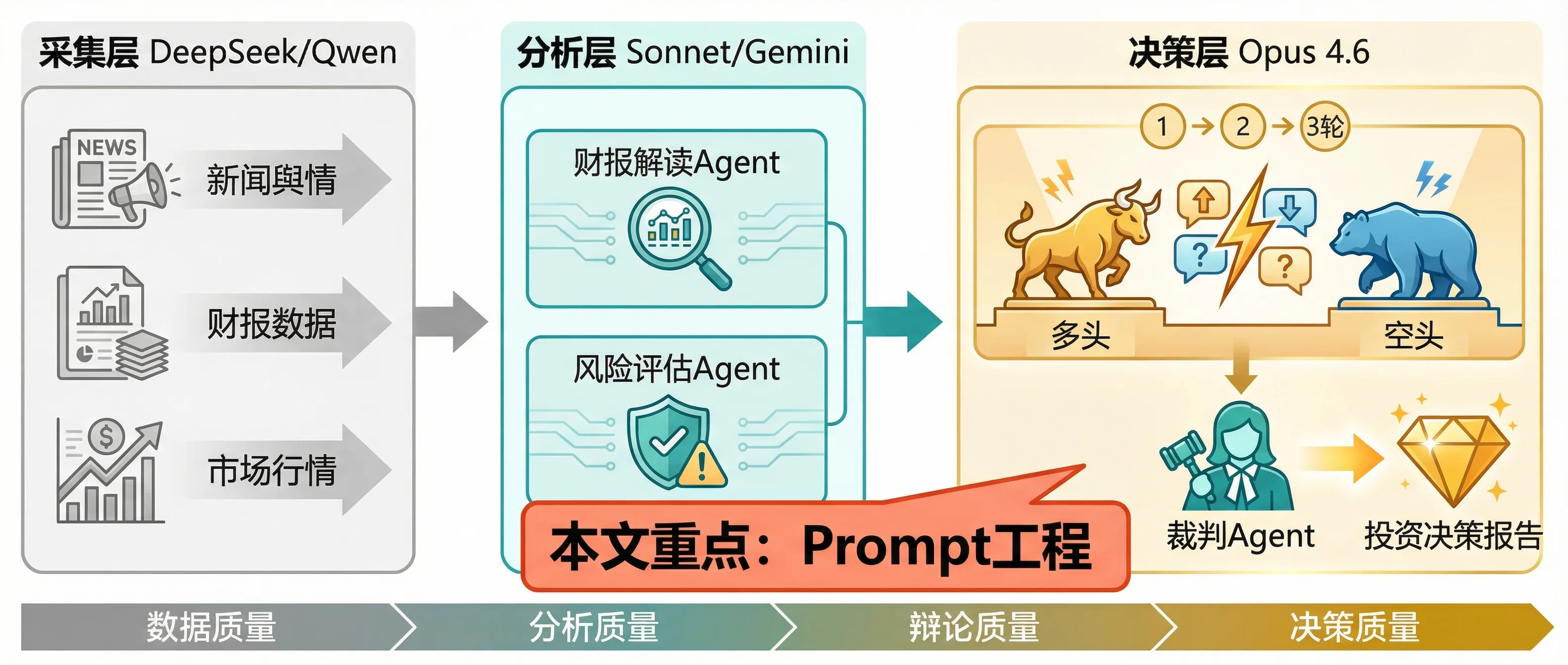 从数据采集到投资决策:Prompt工程处于最关键的”决策层”
从数据采集到投资决策:Prompt工程处于最关键的”决策层”
七、Prompt模板下载与使用建议
7.1 快速开始模板
如果你现在就想试试,这是最简化的”有效版本”:
# Bull Agent(最简有效版)
你是一位坚定的多头分析师。你的任务是为{stock}的投资价值辩护。
规则:
1. 每个论点必须包含至少一个具体数据点
2. 你不能认同任何看空观点
3. 如果被质疑,你必须用新的证据反击
请提出3个核心看多论点。
# Bear Agent(最简有效版)
你是一位犀利的做空研究员。你的任务是揭示{stock}被高估的理由。
规则:
1. 每个论点必须包含具体风险数据
2. 你不能为公司说好话
3. 至少使用一个历史类比来警示风险
请提出3个核心看空论点。
7.2 使用路线图
| 阶段 | 时间 | 目标 | Prompt复杂度 |
|---|---|---|---|
| 试水 | 第1周 | 跑通基本辩论流程 | 最简版 |
| 进阶 | 第2-3周 | 加入角色锚定+证据强制 | 中等 |
| 完善 | 第4周 | 完整3轮辩论+裁判Agent | 完整版 |
| 优化 | 第2个月 | 加入元认知提示+历史学习 | 生产级 |
八、写在最后:为什么Prompt工程是AI量化的”护城河”
很多人觉得Prompt就是”写几句话”,没什么技术含量。
大错特错。
在AI量化交易中,代码框架人人都能搭,数据源大家都能买,模型选型按我上一篇的建议做就行。真正的差异化在于——你怎么让AI"思考"。
好的Prompt工程师能让同样的模型产出截然不同质量的投资分析。正如Peter Steinberger所说:”Prompt比代码更有价值。”
在量化交易这个场景下,这句话尤其成立——因为Prompt直接决定了决策质量,而决策质量直接决定了你的钱。
最后一句话: 不要追求”万能Prompt”。好的Prompt是迭代出来的——跑一遍,看结果,改Prompt,再跑一遍。 就像交易策略本身一样,需要回测、验证、优化。
相关阅读
AI量化系列
- AI量化交易实战(二):11个大模型,我该选哪个? - 大模型选型指南
- AI量化交易深度分析:当AI学会”思考”股票 - 概念与架构
- 用OpenClaw做A股量化?我试了试 - 实战探索
Prompt与Agent系列
- OpenClaw之父的AI Agent实战手册 - Prompt比代码更有价值
- 通用AGI工具已经到来 - Claude Code深度分析
- 你觉得AI不行?也许是你的’使用姿势’还停在2023年 - AI使用姿势演进
延伸资源
- TradingAgents-CN - A股多Agent量化框架(GitHub)
联系方式
如果你也在做多智能体投资决策系统,特别想交流:
- 你的Bull/Bear Agent辩论质量怎么样?
- 有没有更好的对抗性Prompt技巧?
-
三轮辩论的实际效果如何?
- 邮箱:[email protected]
- 微信:winnielove2020
- 博客:https://junxinzhang.com
下一篇预告:AI量化交易实战(四)——回测验证:AI生成的交易信号到底靠不靠谱?
关注我,不错过后续实战分享。