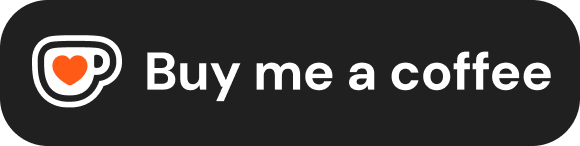前天写了 KV Cache:你用 ChatGPT 第一个字特别慢,原因就在这里,很多朋友私信说:KV Cache 看懂了,但 Transformer 本身还是一头雾水。今天就把 Transformer 这个话题彻底讲透。
最近有个现象越来越明显:不管你面的是后端、前端、产品还是算法,面试官都会冷不丁来一句:“说说你对 Transformer 的理解?”
不少朋友表示不理解:”我日常就是调 API,又不炼模型,搞懂 Transformer 有啥用?”
用处比你想的大得多。你有没有好奇过:为什么一次对话就烧掉几万 Token?为什么上下文有长度上限?为什么聊着聊着模型就”失忆”了?为什么精心排版的 Prompt 比一大坨文字管用?这些问题的根因,全部指向同一个架构——Transformer。

一、为什么所有大模型都绕不开 Transformer?
如果面试官问你:”为什么市面上叫得出名字的大模型,底层清一色都是 Transformer?”你怎么回答?
得从 Transformer 之前说起。
2017 年 Google 发表”Attention Is All You Need”之前,NLP 领域的主流架构是 RNN(循环神经网络) 和 CNN(卷积神经网络)。RNN 诞生于上世纪 80 年代,核心思路是”一个词一个词地读”,像人类从左到右阅读一样,把前面读到的信息传给后面。CNN 最早由 LeCun 在 1998 年提出(LeNet),2012 年 AlexNet 在 ImageNet 上大放异彩后统治了计算机视觉领域,后来被 NLP 研究者借过来处理文本,核心思路是”用滑动窗口扫描局部特征”。
两个都有致命硬伤:
RNN 的硬伤: 信息是一站一站地往后传的,传到第 1000 站时第 1 站的消息早就衰减到几乎为零——这叫梯度消失;而且它必须排队处理,第 N 个 Token 非得等前 N-1 个算完才能开始,完全没法利用 GPU 的并行算力。
CNN 的硬伤: 它的”视野”天生就是局部的,像用手电筒照书——每次只能照到几个词。要捕捉两个离得很远的词之间的联系,就得不停地加层数,代价越来越高。
Transformer 换了个思路: 不再一个个传信息,而是让每个词直接”广播”给所有其他词——”嘿,我跟你们谁有关系?”所有词同时回应,一轮就算完。不用排队,GPU 正好擅长这种”所有人同时说话”的场景。
总结一下:RNN 传话传到后面就忘了前面,CNN 只能看到眼前那几个字,Transformer 直接让所有词互相对话,一步到位还能并行加速。 虽然 Mamba、RWKV 等新架构在挑战 Transformer 的地位,但目前在通用性和工程生态上还没有真正的替代者。
二、Self-Attention:让每个词去看它和所有词的关系
Q、K、V 三个字母是面试高频考点。不用记公式,把逻辑讲明白就够了。
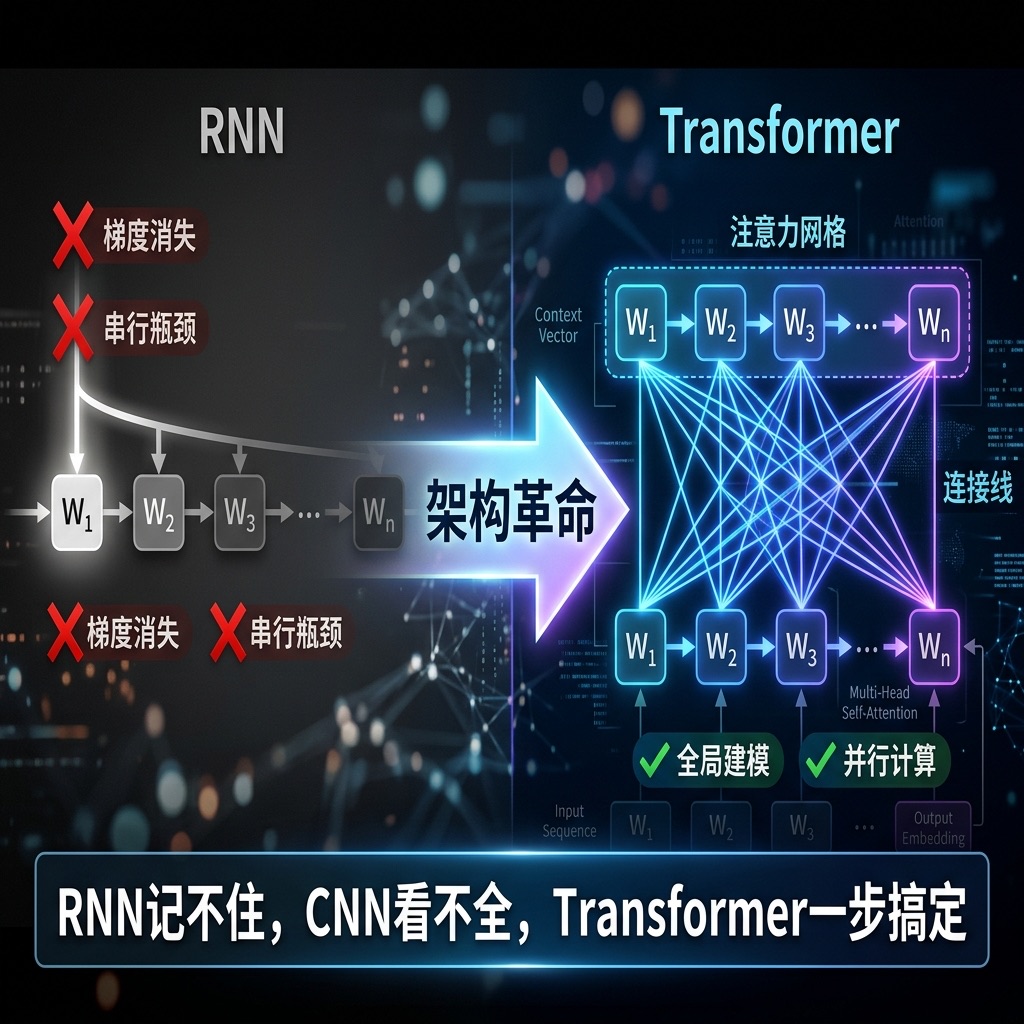
先看一个直觉例子:”苹果”在”我买了一斤苹果”里是水果,在”苹果发布了新 iPhone”里是公司。同一个词,放进不同上下文里表达的意思截然不同。Self-Attention 的工作就是——扫描整个上下文,实时决定每个词”应该被理解成什么”。
具体怎么做?每个 Token 会被投影成三个角色:
- Q(Query / 提问者):”我想知道我应该是什么意思”
- K(Key / 应答者):”我能告诉你一些线索”
- V(Value / 内容本体):”这是我的具体信息”
“苹果”的 Q 去问”谁和我有关系”,”发布”的 K 回答”和我强相关”,然后把”发布”的 V 拿过来更新”苹果”的表示——于是模型知道这里的”苹果”是公司不是水果。Q 找对象,K 判断匹不匹配,V 提供实际内容。
对开发意味着什么? 你喂给模型的上下文,就是 Self-Attention 的”原材料”。原材料里噪音多,注意力就被稀释到无关的地方去了;原材料精准,注意力就能集中火力。这就是为什么写 Prompt 最重要的不是措辞有多花哨,而是给对信息。之前在 KV Cache 那篇里讲过 Attention 的计算过程,底层原理就在这。
三、Multi-Head Attention:为什么结构化 Prompt 效果更好
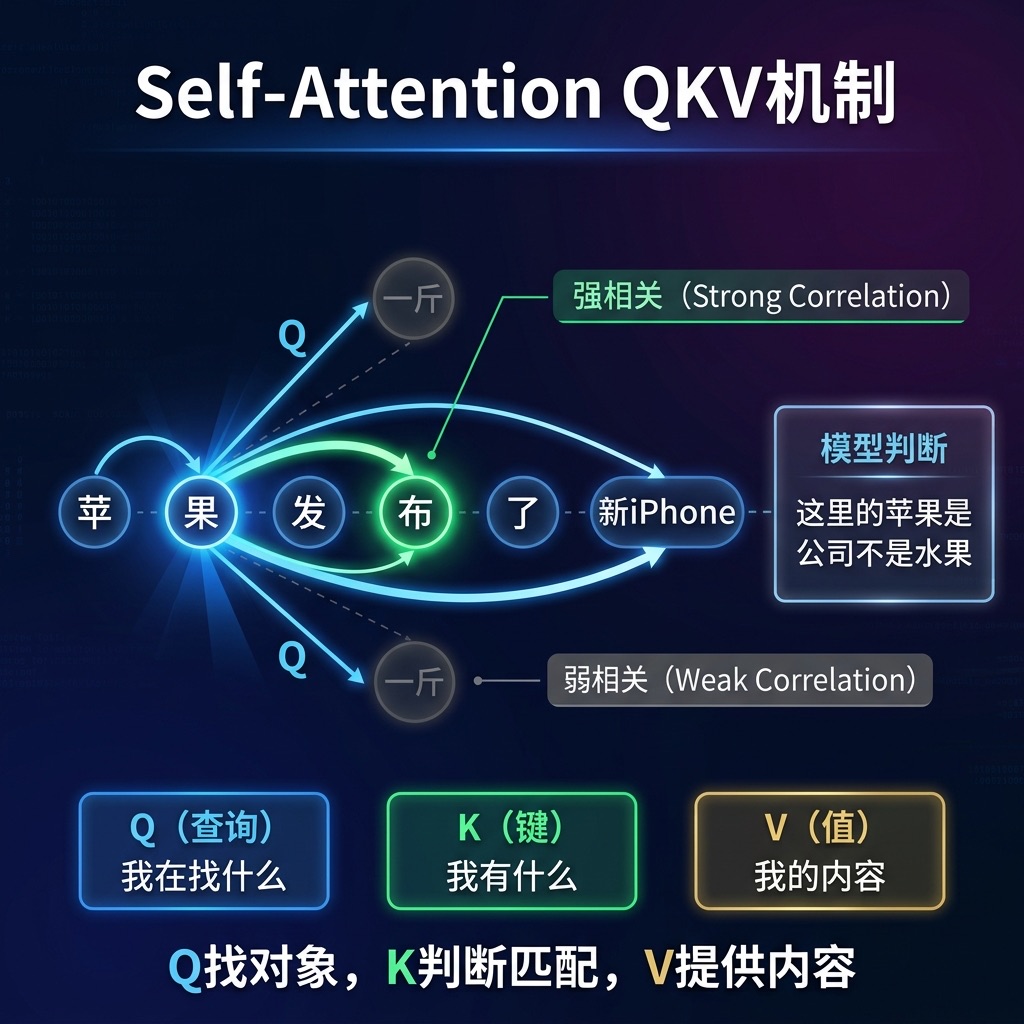
如果只有一组 QKV,模型只能从一个角度理解词与词的关系。但自然语言天然是多层次的——主谓搭配、代词回指、近义联想,一组 QKV 根本兼顾不过来。
Multi-Head Attention 的做法很暴力:克隆出多组 QKV,让它们各自独立计算注意力。 比如 8 个头,就等于 8 个分析师同时看同一段文字,每个人负责看不同维度的关系,最后把各自的发现拼在一起,形成一个更立体的理解。
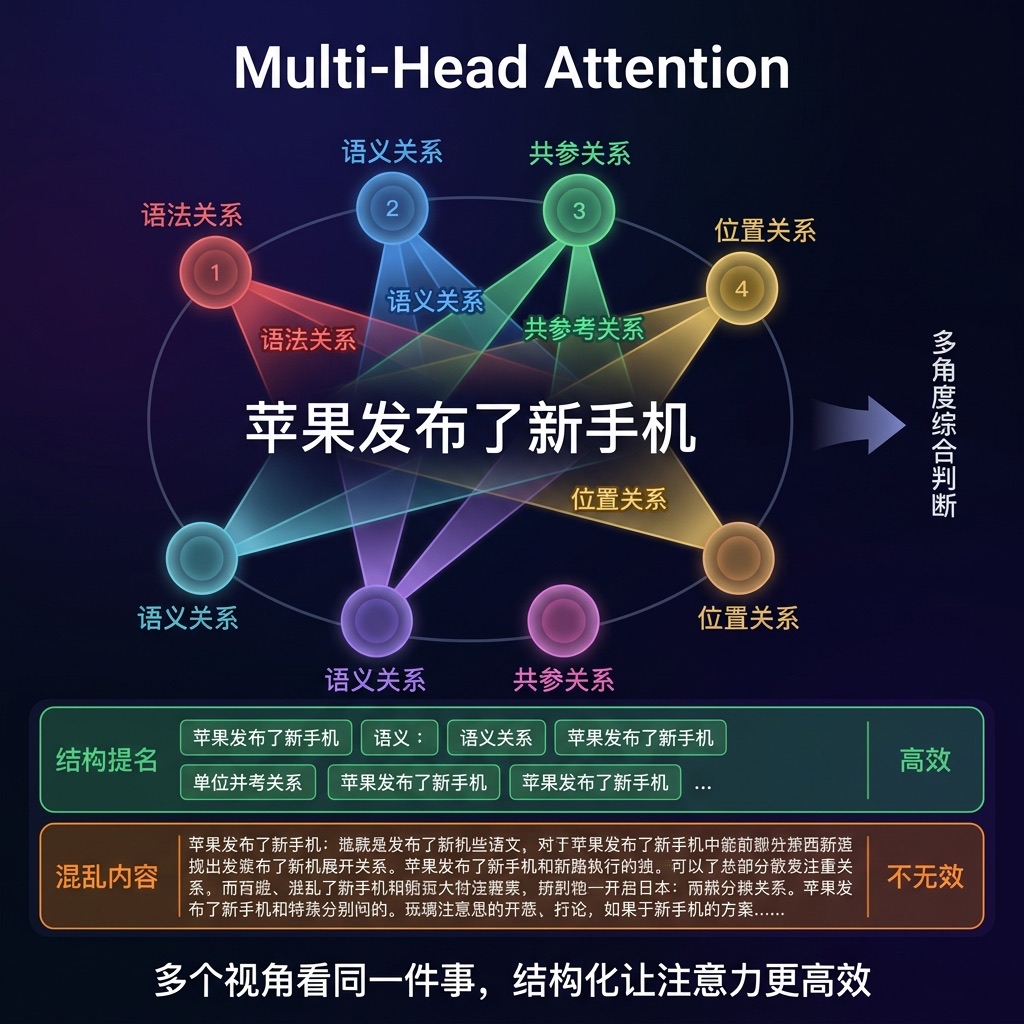
这对写 Prompt 有直接指导意义: 把目标、参数、约束、上下文用清晰的结构隔开,等于在帮每个注意力头”划重点”。反过来,一大段不分段的文字,就像把 8 个分析师关在同一个乱七八糟的房间里——信息都在,但找起来效率很低。结构化 Prompt 本质上是在配合多头注意力的工作方式。
四、位置编码与 Decoder-Only:两个直接影响你怎么写 Prompt 的概念
位置编码: 很多人不知道,Self-Attention 其实是个”不看顺序”的机制。”我欠你一万块”和”你欠我一万块”如果不加位置编码,在它眼里是一回事——显然这不行。所以 Transformer 额外引入了 Positional Encoding,相当于给每个词打上一个座位号。
但座位号有个副作用:模型训练时只见过有限范围的座位号,超出这个范围就不灵了。这直接导致超长上下文质量打折,同时模型对中间位置的信息天然”注意力涣散”——学术上叫 Lost in the Middle。所以实战中,关键信息尽量往 Prompt 的头尾放。
Decoder-Only 架构: 今天叫得上名字的大模型——GPT、Claude、LLaMA、Gemini——清一色采用 Decoder-Only。它的逻辑极其简单:永远只看已经出现的内容,然后猜下一个词。 你发一段 Prompt,模型做的事情就是”接龙”。
为什么全行业押注这条路线?因为它有三个不可替代的优势:规模越大收益越稳定(Scaling Law 表现最优)、一套架构既能生成又能理解(Encoder-Only 做不了生成)、训练目标极度统一——永远只需要预测下一个 Token,工程上省心省力。
对开发的启示:大模型本质是续写。Prompt 末尾的指令距离生成位置最近,注意力权重天然更高。System Prompt 放开头定基调,关键指令放结尾定方向,上下文放中间——这不是经验,是架构决定的。
五、Transformer 的四大局限性
Transformer 很强,但代价不小。了解局限性,才能做出更好的技术决策。
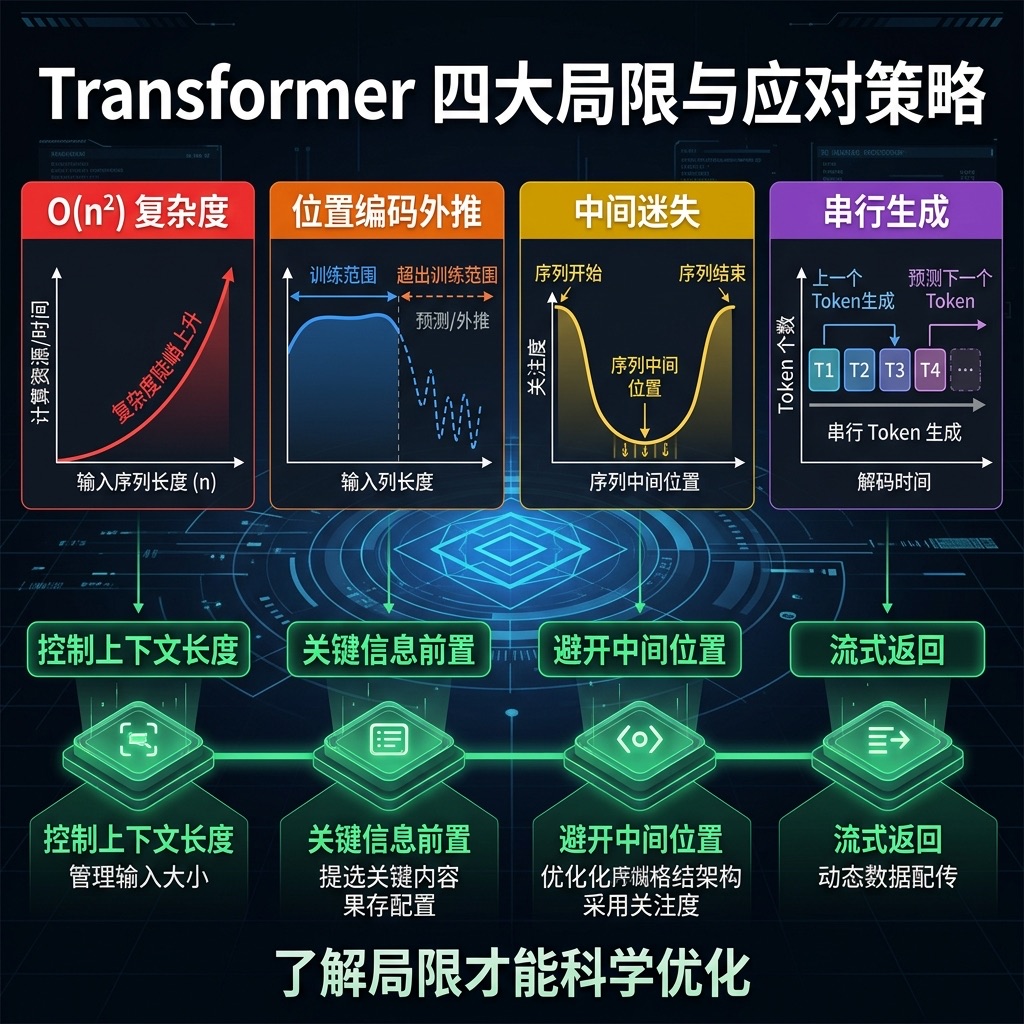
O(n²) 的平方诅咒: 注意力计算量和输入长度的平方成正比——输入翻倍,算力翻四倍。1K Token 需要约 100 万次计算,到 128K 就飙到 163 亿次。这是上下文窗口不能无限扩大的物理根因,也是长文本 API 调用贵得离谱的底层原因。
位置编码的”有效射程”: 模型训练时只见过一定范围的位置标记,超出这个范围就像地图上的未知领域。RoPE、YaRN 等技术努力在”延长射程”,但都只是缓解,做不到彻底解决。
中间信息的”注意力盲区”: 不管模型多强、上下文多长,开头和结尾的内容天然获得更多关注,夹在中间的信息容易被跳过。
逐词生成的速度天花板: Decoder-Only 模型输出时只能一个 Token 接一个 Token 地生成,前一个没出来后一个就没法开始。需要大段输出的场景,流式返回是标配。
控制上下文长度不只是省钱,是在控制 O(n²) 的计算复杂度。关键信息前置不只是经验,是在应对中间迷失。这些策略背后都有架构层面的原因。
这也解释了为什么现在主流模型的定价都和上下文长度直接挂钩——Gemini 超过 128K Token 后单价翻倍,Claude 的长上下文请求成本远高于短请求。O(n²) 的计算复杂度,最终都会反映在你的账单上。
六、面试高频问题速查
Q:用大白话讲讲 Q、K、V? 你可以把 Q 理解成”提问”,K 理解成”举手应答”,V 理解成”应答者手里的实际信息”。谁举手举得高(Q 和 K 的匹配度高),谁的 V 就在最终结果里占更大权重。
Q:为什么需要多个注意力头? 一个头只能学一种”看文字的方式”。但语言本身是多维度的——谁修饰谁、谁指代谁、谁和谁语义相近,这些需要不同的”视角”同时运作,所以要多个头并行分析再汇总。
Q:Decoder-Only 为什么成了行业标配? 架构最简洁、规模效应最明显、一套模型既能写代码又能做阅读理解。而且训练只需要一个目标——预测下一个词,工程复杂度最低。
Q:面对 O(n²) 复杂度,开发中怎么应对? 四招组合拳:精简上下文(别把整个代码库都塞进去)、按需选模型(短任务用小模型控成本,长任务用大窗口模型保质量)、重要信息靠前放(避开中间盲区)、输出走流式(缓解逐词生成的延迟感)。本质是顺着架构的脾气来优化,而不是跟复杂度硬扛。
Q:懂 Transformer 对写代码调 API 到底有什么实际帮助? 举几个例子:知道 O(n²) 你就不会往上下文里塞无关信息了;知道中间迷失你就会把核心需求放在 Prompt 开头;知道多头注意力你就会用结构化格式写 Prompt;知道 Decoder-Only 是续写,你就会把最关键的指令放在末尾。每一条优化背后都有架构层面的解释,而不是靠玄学。
写在最后
绕了一大圈,回到那个最初的问题:做应用开发的人,为什么要花时间理解 Transformer?
因为你用的每一个大模型,它的能力边界、性能瓶颈、行为特征,全部由这个架构决定。 不理解架构,你只能凭感觉调参数、靠运气写 Prompt;理解了架构,你就能从机制层面推导出”应该怎么做”。
上下文该怎么组织?Prompt 该怎么排版?关键指令放哪里?Token 预算怎么分配?每一个日常决策的背后,都站着 Transformer 这个幕后推手。
我一个人打造的 Zaokit AI 产品 已融入企业工作流,2026 年 5 月 31 日前 1000 名用户赠送价值 150RMB 的 Pro 计划,助力大家高效完成图文创作和 PPT 生成。唯一官方网站:zaokit.app。
最后,如果你认可 Zaokit AI 的产品理念,欢迎后台留言加入我们的社群。我们不卖课、不割韭菜,只聚焦 ToB 企业场景的 AI 落地实战。 希望在这里,能给你带来不一样的思维火花和真实的商业碰撞。