前两天写了 面试必问 Transformer 和 KV Cache 推理加速,不少朋友私信问:有没有系统性的课程推荐?最好是偏工程实战的,不要又从零推一遍矩阵公式。
还真有。DeepLearning.AI 刚上线了一门 Transformers in Practice,和 AMD 深度合作,由 AMD 工程副总裁 Sharon Zhou 主讲。免费版可以看所有视频和基础代码。
看完之后我的第一反应是:这不是「又一门 Transformer 课」,而是第一门真正面向生产工程师的 Transformer 课。

一、这门课不讲什么
先说它不是什么——
不是又一遍 Attention is All You Need 的数学推导。不会让你对着 Softmax(QKᵀ/√d)V 手算矩阵乘法。
不是又一套调 Prompt 的玄学技巧。不会教你”请用专业语气回答”之类的话术。
更不是又一个从零写 Transformer 的玩具项目。你不需要用 PyTorch 手搓 Multi-Head Attention 才能理解它在做什么。
这门课做的事情很直接:把 Transformer 的黑箱给你拆开,让你用手摸到里面的零件。
二、亲手看着幻觉是怎么长出来的
课程第一个模块就直击要害——自回归循环(Autoregressive Loop)。
它会让你亲手操作模型的生成过程:一个 token 一个 token 地生成,每一步都展示当前的概率分布。你能清清楚楚看到:模型在第 N 步有 60% 的概率选”天气”,30% 选”温度”,但采样偶然命中了那 2% 的”恐龙”——然后接下来的文本就开始往不可控的方向狂奔。
幻觉不是玄学,它就是概率采样的一次走偏,被自回归循环放大了。
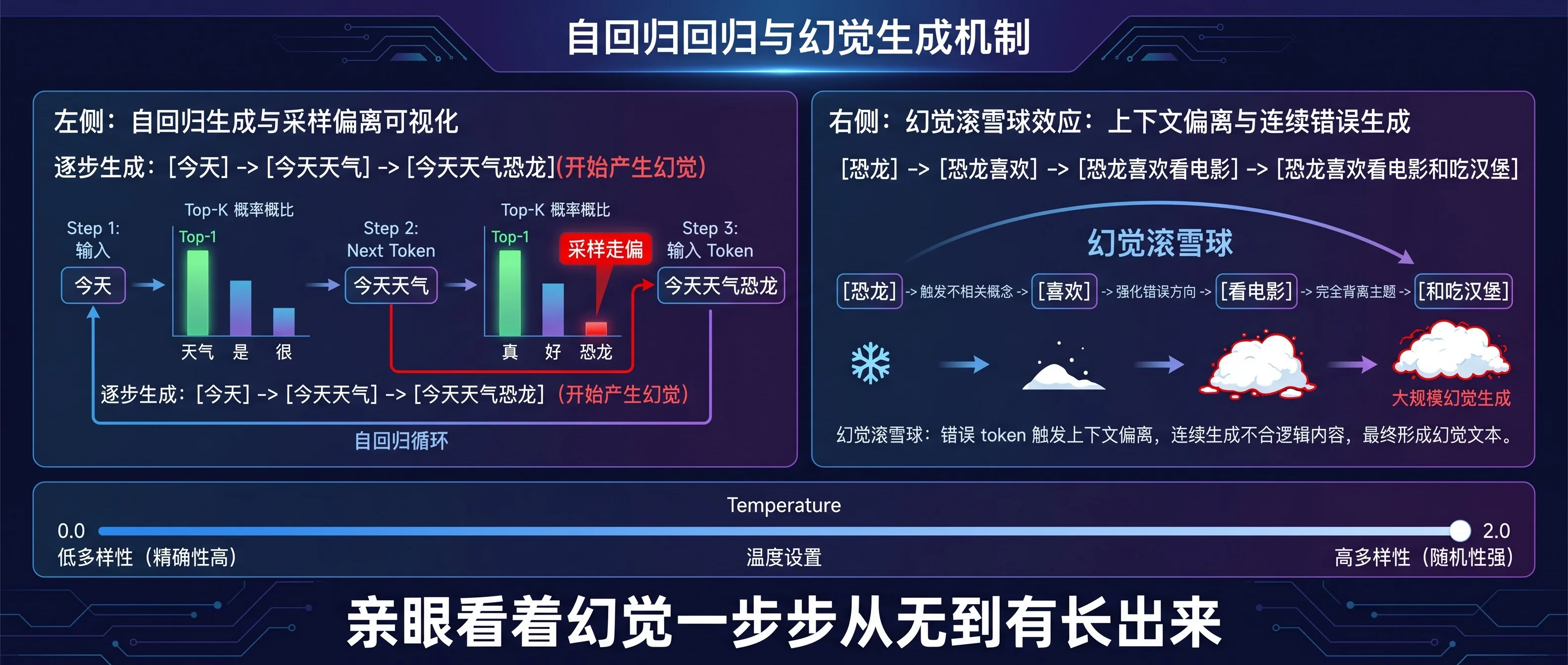
更绝的是 temperature 可视化环节——课程直接给你一个滑块,拖动 temperature 从 0 到 2,实时看到输出从”高度确定的复读机”到”天马行空的胡说八道”之间的连续变化。你终于能直观理解:temperature 不是一个魔法参数,它就是在拉伸或压缩概率分布的形状。
这个模块还覆盖了 RAG、结构化输出(Constrained Generation)和 Chain-of-Thought 推理——关键是,它把这些技术统统放回自回归循环这一个框架里解释。你会发现,所有这些花哨的技巧,底层都是在同一个 while 循环里做文章。
三、每个注意力头都在管什么
第二个模块进入模型内部——Attention 的可视化。
这部分最让我震撼的是 Interpretable Attention Heads 环节。课程让你点开模型的每一层、每一个注意力头,直接看到不同头的”职责分工”。
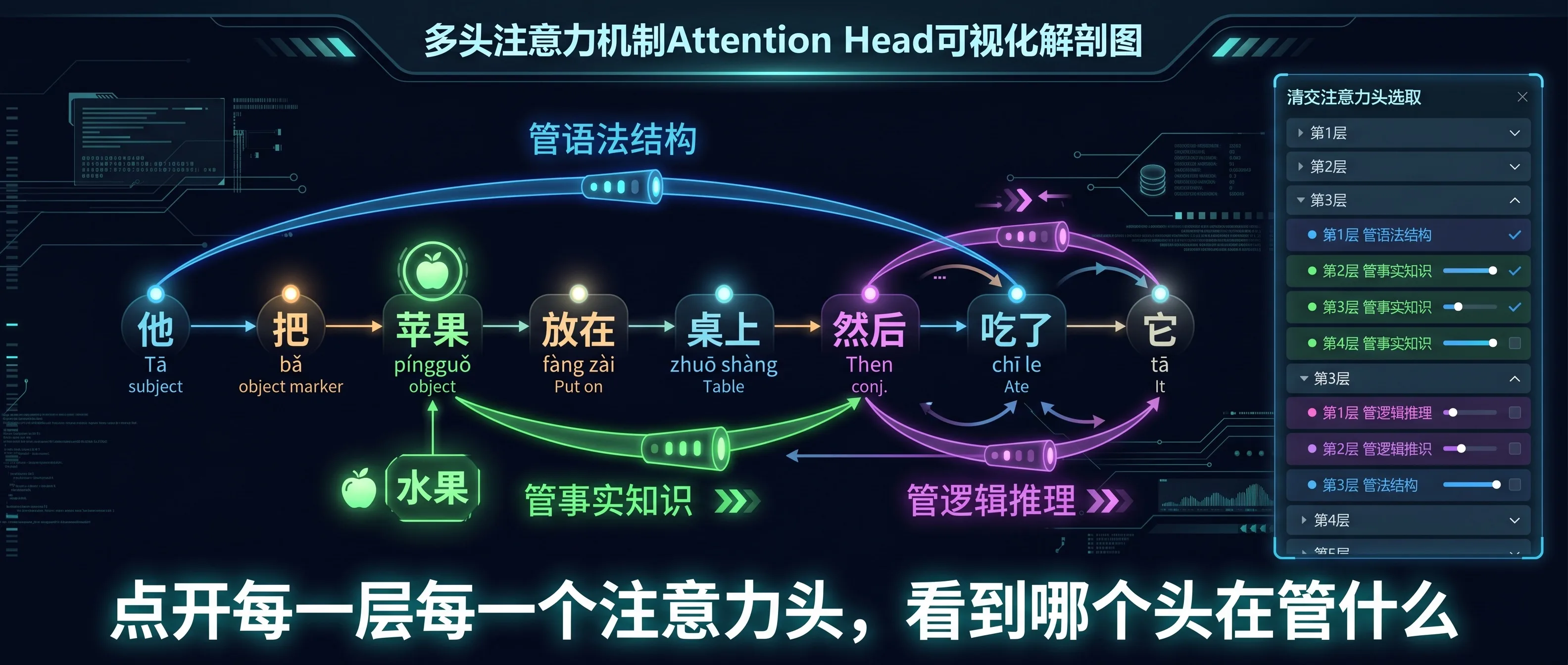
有的头在追踪语法结构——主语和谓语之间的高亮连接一目了然;有的头在管事实性关联——”苹果”和”公司”或”水果”之间的注意力权重截然不同;还有的头在处理逻辑推理——”因为”和”所以”之间的因果链条。
Multi-Head Attention 不再是一个抽象概念,而是一组你可以逐个检查的”分析师团队”。 之前在 面试必问 Transformer 里讲过多头注意力的原理,这门课直接给你工具去验证。
这个模块还包括位置编码(Positional Encoding)的可视化、中间层解码(Decoding Intermediate Layers)——你能看到同一段输入在模型的第 1 层、第 12 层、第 24 层分别”理解成了什么”。底层还是糊的,到高层才逐渐清晰——这种渐进式理解的过程,看一遍就忘不了。
四、推理优化:生产工程师每天都在踩的坑
第三个模块是我认为最值钱的部分——推理优化。
如果你在做 LLM 的生产部署,以下场景一定不陌生:推理慢到用户投诉、GPU 显存 OOM、推理成本每月烧掉一台车。
以前所有人的解决方案都是两个字:加钱。 换更大的 GPU,加更多的机器,用更贵的云实例。
这门课告诉你一个残酷的事实:大部分推理延迟根本不是参数量的问题,是内存带宽的问题,是注意力计算的问题。

课程把四大优化技术逐一拆解:
量化(Quantization): 把模型参数从 FP16 压缩到 INT8 甚至 INT4,模型体积直接砍半甚至砍到四分之一,推理速度翻倍,精度损失几乎可以忽略。之前在 百万预算私有化部署 里提过量化对显存的影响,这门课把底层原理讲透了。
KV Cache: 之前写过 KV Cache 那篇文章的读者应该不陌生——把已经算过的 Key 和 Value 存起来,避免每个 token 都重算,把 O(n²) 的浪费压成 O(n)。课程里有实际代码示例,直接跑。
Flash Attention: 这是对 GPU 内存层级做手术——把 Attention 的计算从 HBM(慢但大)搬到 SRAM(快但小),通过分块计算(Tiling)减少内存搬运次数。一行代码的切换,推理速度可以翻 2-3 倍。
投机解码(Speculative Decoding): 用一个小模型快速”打草稿”,大模型只负责”审核”。小模型一次性猜 5-10 个 token,大模型并行验证,命中率高的场景下速度提升 3-5 倍。
每一个技巧的核心思路都不复杂,但组合起来可以让你的推理成本降低 60-80%,而且不需要换硬件。这才是生产工程师最需要的知识。
五、终于不只讲 CUDA 了
还有一个细节值得单独说:这门课是和 AMD 深度合作的,由 AMD 工程副总裁 Sharon Zhou 亲自主讲。
这意味着什么?意味着课程里讲的优化技术,不是只针对 NVIDIA 生态的。量化、KV Cache、Flash Attention 这些技术本身是跨硬件的,但此前几乎所有教程都默认你用的是 CUDA + A100/H100。这门课终于开始讲硬件感知的优化——GPU 内存层级怎么影响推理速度、不同硬件架构下同一个优化技术的表现差异、怎么根据你手上的硬件选择合适的优化组合。
终于有人把”优化推理”这件事从 CUDA 的小圈子里拽出来了。
写在最后
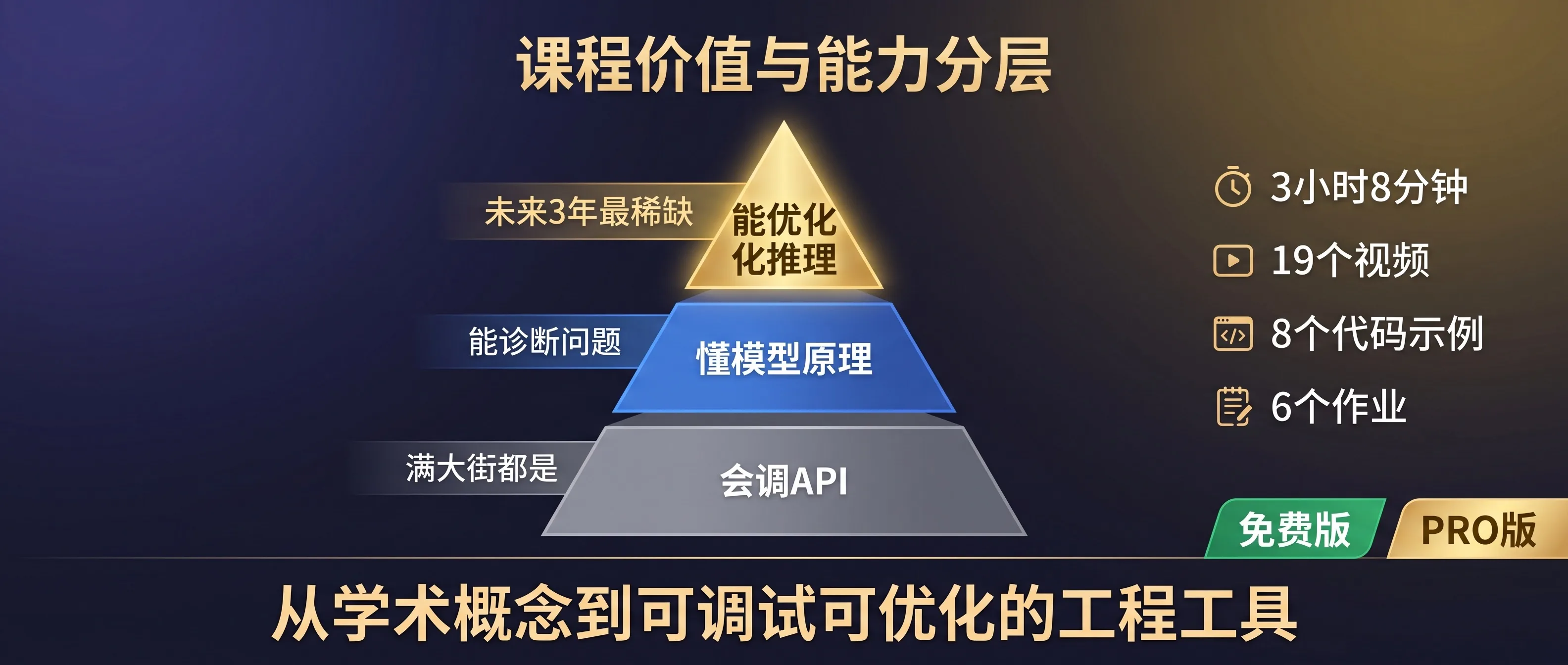
会调用 API 的人已经满大街都是了。但能看穿模型内部,能诊断推理瓶颈,能用量化 + KV Cache + Flash Attention + 投机解码的组合拳把成本打下来的人——这才是未来三年最稀缺的。
这门课最大的价值,不在于它教了多少新知识,而在于它终于把 Transformer 从一个学术概念,变成了一个你可以摸得到、可以调试、可以优化的工程工具。
几个关键数字:总时长 3 小时 8 分钟,19 个视频 + 8 个代码示例 + 6 个作业,全部是干货没有废话。免费版可以看所有视频和基础代码,PRO 版可以做 Graded Assignment 拿证书。
课程链接:Transformers in Practice - DeepLearning.AI
我一个人打造的 Zaokit AI 产品 已融入企业工作流,2026 年 5 月 31 日前 1000 名用户赠送价值 150RMB 的 Pro 计划,助力大家高效完成图文创作和 PPT 生成。唯一官方网站:zaokit.app。
最后,如果你认可 Zaokit AI 的产品理念,欢迎后台留言加入我们的社群。我们不卖课、不割韭菜,只聚焦 ToB 企业场景的 AI 落地实战。 希望在这里,能给你带来不一样的思维火花和真实的商业碰撞。