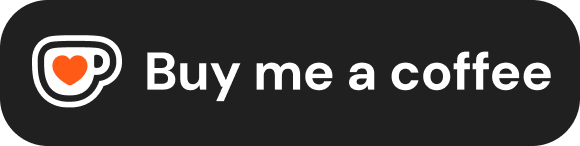做 Zaokit 早期 pipeline 的时候,我在一个 prompt 上耗了将近两周。换措辞、加示例、调结构——像在跟一个脾气捉摸不定的合作者反复磨合。
磨完之后,任务形态变了。从”写一段文案”变成了”理解用户意图→检索参考→生成初稿→多轮迭代”。我才意识到那两周的调教根本对不上号——它解决的是个假问题。
这件事在行业层面已经演进了三轮。每一轮都不是有人坐下来设计的,而是被上一轮撞了墙之后逼出来的。理解 LLM Engineering 的最好方式,是回到每次迁移的现场:是什么撞了墙,又是什么在等待。

| 阶段 | 任务形态 | 核心工作 | 瓶颈 |
|---|---|---|---|
| Prompt Engineering | 静态单次 | 人工优化措辞 | 解决不了多步任务 |
| Context Engineering | 动态多步 | 程序化编排信息流转 | 硬编码规则限制模型自主性 |
| Harness Engineering | 自主运行 | 放手+划边界 | 环境设计、eval、治理 |
一、Prompt Engineering:对着水晶球许愿的时代
ChatGPT 上线之初,所有人都在摸索:换措辞、加前缀、调语气,看哪种说法能换来更好的输出。
这个摸索期沉淀出了一套工程实践:Few-shot 示例、Chain-of-Thought 推理、角色指定、输出格式约束。GitHub 上涌现大量 prompt 模板库,大家交换 prompt 的方式像交换咒语——这条能召唤出好代码,那条能让翻译更地道。”在 prompt 末尾加一句’这对我的职业生涯非常重要’,输出质量会提升”这类发现,当时是真实有效的经验。
这些技巧确实有用。CoT 在当时能把推理任务准确率拉高十几个百分点,一个精心设计的 prompt 和随手写的 prompt,输出质量可能差两个等级。
我自己也完整走过这个阶段:在 prompt 里穷举所有边界情况,试图把每个细节都事先告诉模型,希望它按照我想象的方式输出。有时候有效,有时候完全随机,根本摸不清背后的规律。
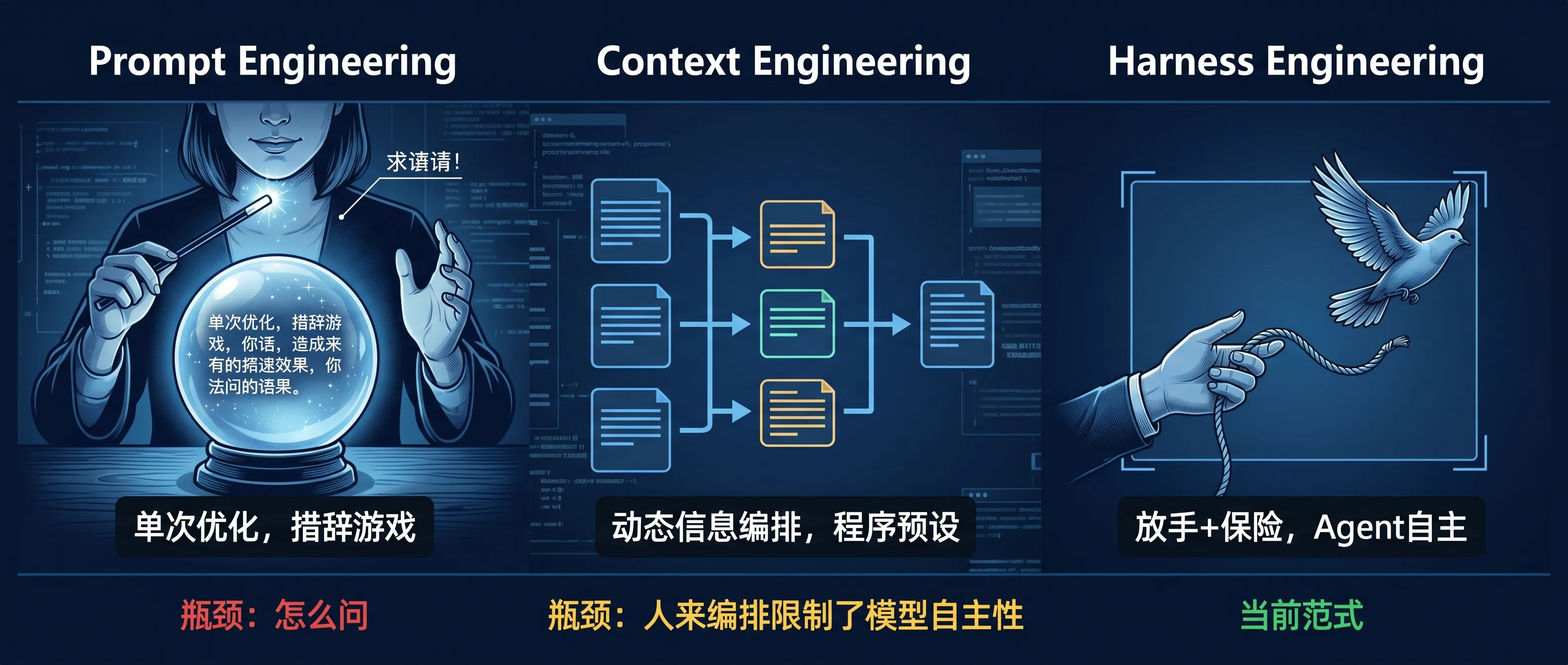
但 Prompt Engineering 有一个根本局限:它是单次任务的优化框架。 写一封邮件、翻译一段话、解释一个概念——你在发出 prompt 的那一刻就完整地知道需要什么,也完整地知道模型该看什么。
然后模型开始支持工具调用了。任务从”问一个问题”变成了”跑一个流程”。你发现,措辞再完美,如果模型看到的信息是错的或不够的,输出就是错的。瓶颈从怎么问移到了给它看什么。
二、Context Engineering:当任务不再是一句话能说清的
Prompt Engineering 时代,任务是静态的。但真实世界的任务很少是静态的。
你让 agent 修一个 bug。一开始只知道”用户报了个 bug”。Agent 搜了日志,发现是支付模块的问题;读了支付模块代码,定位到具体函数;改了函数,LSP 报了三个新的 type error;跑测试,两个 pass 一个 fail,才知道还有边界情况没处理。每一步的输出决定了下一步该做什么、该看什么。任务的全貌不是一开始能定义的,它在执行过程中逐步展开。
这就是 Prompt Engineering 撞的墙:你没法在一次 prompt 里把所有信息组织好,因为那些信息要等前面步骤执行完才会浮现。
Context Engineering 真正做的新事是:在一个动态展开的多步任务里,管理步与步之间的信息流转。具体回答的问题:
- 上一步的结果怎么流入下一步的 context?
- 环境反馈(LSP 报错、测试失败)怎么注入?
- 对话历史越来越长,哪些压缩、哪些保留?
- 外部检索的信息,在哪一步注入、注入多少?
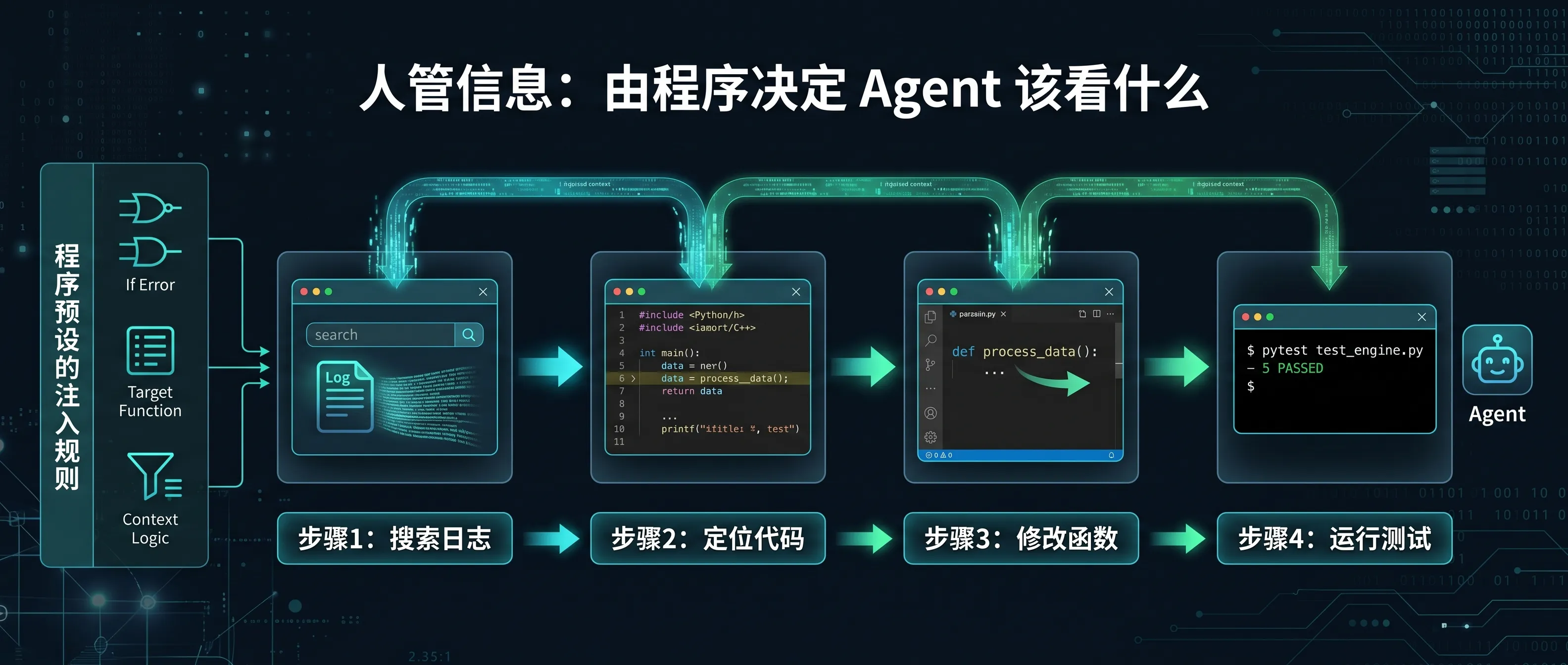
我用 Cursor 和 Claude Code 做 Zaokit 开发的体感就是这样——在一个大型任务里,最难受的不是模型不够聪明,而是信息流转出了问题:前一步生成的文件没有被正确引用进来,测试报的错误没有注入到下一步的 context,模型靠猜而不是靠看到真实结果做决定。
Cursor 是这套逻辑的典型产品。你改了一个函数签名,它不是把整个代码库都塞进 context,而是动态检索相关调用方注入;你修完这些文件,测试报了新错误,它再把测试文件和错误信息拉进来。每一步看到什么,取决于上一步发生了什么。Lovable、Bolt 是同样的路数——编辑器、LSP、构建系统产生的环境反馈,被程序自动注入到下一轮 context。
2025 年 6 月,Karpathy 发推给了这套实践一个名字:
“Context engineering is the delicate art and science of filling the context window with just the right information for the next step.”
14k likes。注意他用的动词:filling。是外部在填,不是模型自己在找。这些实践在命名之前就已经存在了,Karpathy 的贡献是精确抓住了本质:任务动态展开,但管理这个过程的规则是静态的、人预设的。
Context Engineering 也有天花板。 Microsoft 和 Salesforce 的研究发现,随着多轮对话推进,模型性能平均下降 39%,即使是最强的 o3 也从 98.1% 掉到 64.1%——这被叫做 context rot。信息管理本身会到达极限。
但更根本的问题不是 context rot,而是:当模型能力已经超过人类硬编码的规则时,人来做信息编排反而成了瓶颈。模型有能力判断哪些信息重要、下一步该看什么,但 context engineering 的框架不给它这个权力。 它把一个已经足够聪明的 agent 当成了被动的信息接收者。
瓶颈再次移动:从”人怎么替 agent 编排信息”到”怎么让 agent 自主编排,同时确保它不失控”。
三、Harness Engineering:放手,然后上保险
Harness Engineering 不是某人坐下来设计出来的新范式,是 agent 大规模跑起来之后,工程师被现实教育出来的经验。
前提:模型已经强到人来编排信息反而是瓶颈了。
Khan 的 Prompting Inversion 研究给了一个直接证据:一种叫 Sculpting 的精细 prompt 技法,在 gpt-4o 上准确率 97%,超过 standard CoT 的 93%。但到了 gpt-5 上反转了——standard CoT 96%,Sculpting 反而降到 94%。模型越强,人类精心设计的技巧反而成了约束。 你以为在帮它,其实在碍事。
所以 harness engineering 的第一步是放手:不再替 agent 做信息决策,而是给它工具,让它自己去获取需要的信息。能跑 lint、能跑测试、能查看浏览器状态、能检索代码库。Agent 自己决定什么时候用这些工具、用哪个、用多深。
第二步是上保险:给 agent 画明确的能力边界。沙箱隔离、CI 轮数限制、文件权限、架构约束——边界的形态取决于场景。
这两步的顺序很重要。不是先画好框再放手,而是先看它自己能跑到哪里,再从失控的地方划线。边界是从现实里倒推出来的,不是坐在白板前凭空设计的。
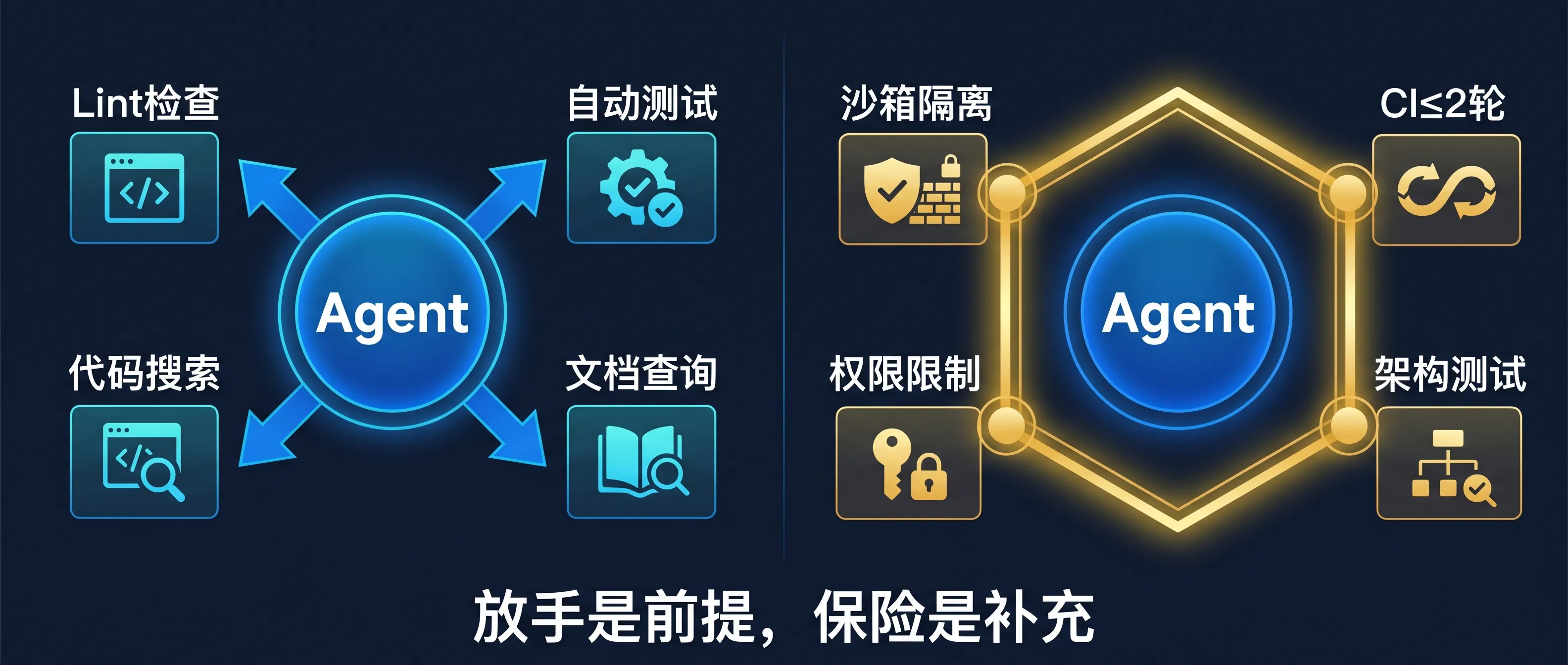
把这两步合在一起:
Harness Engineering 是为 agent 构建运行环境的工程实践。放手:给 agent 工具和反馈通道,让它自主获取信息、自主判断。上保险:给 agent 框定能力边界,确保自主运行不失控。能力边界不是对模型的不信任,而是对非确定性系统的工程纪律。
四、三个案例验证
Stripe Minions:1000 PR/周,全靠 Agent 写
Stripe 自建了一套叫 Minions 的无人值守 coding agent,每周合并超过 1000 个 PR,全部 agent 写的,人只做 review。
放手的部分: Agent 可以跑 lint、跑测试、通过 Sourcegraph 搜代码、通过 MCP 查内部文档。这些工具不是程序在背后替 agent 调,是 agent 自己决定何时用、用哪个。Stripe 工程师总结了一条设计原则:”shift feedback left”——能在本地拦住的不等 CI。Agent 每次 push 后,5 秒内就能跑完一轮 lint 检查。反馈来得越快,agent 自我纠正的成本越低。
上保险的部分: Agent 跑在隔离的 devbox 里,不能访问生产环境和外网。最多跑两轮 CI,不管结果如何都停下来。MCP 连接了 400 多个内部工具,但每个 agent 只能访问经过筛选的子集。
值得一提:Stripe 按子目录条件自动加载的 rule files,不是 harness,是 context engineering——规则加载逻辑是程序预设的,agent 没有选择权。这也能看出螺旋的积层:harness 内部,context engineering 的 pipeline 仍然在运转。
Anthropic Claude Agent SDK:从失败模式倒推边界
Anthropic 做了一个实验:让 agent 自主构建一个完整的 web 应用。Agent 拥有完整开发工具链(文件系统、bash、Puppeteer 浏览器控制)。放手之后,立刻暴露出三种失败模式:
- 一口气做太多——试图一次实现所有功能,context 用完留下一堆半成品
- 过早宣布完成——看到已有进度就说”做完了”
- 假装测试通过——标记 feature 完成,但实际没有验证
看到这三条我笑了,因为这几乎是我自己用 Claude Code 跑复杂任务时碰到的同款问题。不是 bug,是 agent 在不受约束的情况下的默认行为模式。
Anthropic 针对每种失败模式加保险:
- 每个 session 只做一个 feature,硬约束,不是建议
- feature_list.json 里 200+ 个 feature 全标为 failing,agent 只能把 passes 字段从 false 改成 true,不能删 feature、不能改描述。用 JSON 不用 Markdown,因为模型更不容易乱改 JSON 结构——数据格式本身就是约束
- 必须用 Puppeteer 做端到端验证,不能只靠 unit test 就宣称”通过了”
这里有一个推进关系值得记住:先放手,发现失控的模式,再针对性加保险。能力边界是从失败模式倒推出来的,不是坐在那里凭空画线。
OpenAI Codex 团队:最极端的案例
OpenAI Codex 团队 3-7 人,5 个月,100 万行代码,1500 个 PR。工程师不再写产品代码,全部精力投入三件事:环境设计、意图明文化、反馈循环构建。
先说放手的部分。
工具链方面,agent 可以跑完整的测试套件、调用自定义 linter、读写文件系统、执行 bash 命令。工具不是事先选好喂给它的,而是随任务需要自主调用。
任务入口设计了一个关键细节——issue 格式是强约束的。每个任务都有机器可解析的结构化验收标准(acceptance criteria),不是自然语言描述。Agent 开始工作之前就知道”什么叫做完了”,不需要猜。
“垃圾回收”是 Codex 团队最有意思的设计之一。不是等 agent 提交才检查,而是持续扫描整个代码库,发现架构 drift(模块边界被侵蚀、重复代码积累、依赖关系跨层)时,自动生成修复任务分配给 agent。环境主动把需要处理的问题推到 agent 面前,agent 自己决定怎么修。 这把”代码库健康”从人工周期性审查变成了持续自动化治理。
再说意图明文化。
这是整个案例里最容易被忽视、但我觉得最值得借鉴的部分。
当工程师不再写产品代码,他们把大量时间花在了让代码库”对 agent 可读”上——不只是注释,而是架构决策的显式文档化:为什么这个模块的边界划在这里?为什么这个函数不能调用那个服务?这些在人类团队里靠口耳相传的隐形契约,全部需要变成 agent 能解析的文本。
翻译成大白话:过去人类靠默契运作,现在得把默契都写出来。 这件事其实早就应该做,只是以前凑合过去了。agent 的出现逼着团队把隐性知识显性化——意外地,这也让代码库对新人工程师更友好了。
上保险:三层硬拦截,只有最后一层需要人。
第一层:自定义 linter,每次提交自动运行,检查代码风格、命名规范、禁用 API 调用。不过就是不能合入,没有人工豁免通道。
第二层:structural tests,专门验证分层架构完整性。Agent 不能写出跨越模块边界的调用——不是靠 prompt 里写”请遵守架构”,而是测试直接 fail。这道拦截让架构约束从”建议”变成了”物理规律”。
第三层:人工 review gate。1500 个 PR,每一个都经过工程师 review 才能合并。这是唯一一道需要人参与的环节。前两层的自动化,反而让这道门的价值更高——工程师 review 时,低级问题已经被拦掉了,他们只需要判断意图和方向是否正确。
负责人 Ryan Lopopolo 总结了一句被广泛引用的话:
“Agents aren’t hard; the Harness is hard.”
最后的结论同样值得摘出来:
“Our most difficult challenges now center on designing environments, feedback loops, and control systems.”
不是模型不够强,是环境设计不够好。这句话我自己用 Claude Code 时深有体会——同一个模型,有没有好的工具链和约束机制,结果差距巨大。最难的工作,已经从”训练更好的模型”转移到了”搭更好的运行环境”。
五、对 Builder 意味着什么
这三个阶段的演进,不只是大厂的工程问题。如果你在用 Claude Code、Cursor,或者在给自己的产品接 AI,这个脉络直接影响你现在该把时间花在哪里。
还在 Prompt Engineering 阶段的你,在为每个任务精心写 system prompt,调措辞、加示例、反复测试。这是起点,也是上限。一旦任务复杂起来,这套东西不够用——不是你写得不好,而是框架本身就不适合多步任务。
进入 Context Engineering 阶段的你,开始关心信息流转:用什么框架管理多步任务?怎么把工具调用的结果注入到下一步?怎么压缩对话历史?这个阶段的工作会让 agent 的稳定性显著提升,但你会越来越明显地感受到自己在做”管信息”的脏活——而且模型往往比你更清楚它需要什么。
站在 Harness Engineering 门口的你,思考的问题变了:不是”怎么写 prompt”,而是”给它什么工具、怎么验证它干的事是对的、如果失控了从哪里兜底”。这个阶段更像在搭运行环境,而不是在跟模型对话。
对独立 Builder 来说,这三个阶段不需要全部自己从头走。Cursor、Claude Code 已经内置了相当成熟的 harness——你可以直接用。但理解背后的逻辑,能让你在工具不够用的时候知道从哪里着手,而不是盲目调 prompt。
六、回头看:一个螺旋的三圈
三个阶段走下来,有一个 pattern 很清楚:每一次演化都不是设计出来的,是上一阶段的做法不够用了,新实践才被逼出来。
每转一圈,三件事同时发生:模型更强了一点,能做更长更复杂的任务;人敢多放手一点,从全程在场到只看结果;新的可靠性问题暴露,催生新的工程实践来兜底。三者不是线性因果,是互相驱动的螺旋。
前一圈不会消失,它变成基础设施。Harness 里还在跑 context engineering 的 pipeline,pipeline 里还在写精心设计的 system prompt。Harness 的约束最终要落地到 agent 能理解的地方,而 prompt 仍然是那个载体。
定量数据支撑这个判断:Epsilla 的实验显示,同一模型、同一 prompt、同一份数据,只换 harness 配置,任务成功率从 42% 跳到 78%。LangChain 在 Terminal Bench 2.0 的测试验证了类似结论:同一个 Opus 4.6,在不同 harness 下的 solve rate 差异超过 60%。模型没变,变的是它有没有被赋予自主获取反馈的能力,以及有没有合理的边界兜底。
螺旋还在转。Harness engineering 之后,下一层瓶颈已经在露出来:
- Eval:agent 跑完了,结果到底好不好?LLM-as-judge 本身有 bias,”评估评估的系统”是一个递归问题。Cisco/Splunk 在 2026 年收购了专注 eval 的公司 Galileo,eval 的产业化正在发生。
- Governance:多个 agent 之间怎么互相认证、怎么审计、怎么管权限?NIST 已经启动了 AI Agent Standards Initiative,计划 2026 年 Q4 发布 Agent Interoperability Profile 初版。
但那是螺旋的下一圈了。
信息来源
核心定义与框架
- Andrej Karpathy, Context Engineering 定义, Twitter/X, 2025.06.25
- Birgitta Böckeler, Harness Engineering for Coding Agent Users, martinfowler.com, 2026.04.02
- Ryan Lopopolo, Harness Engineering: Leveraging Codex in an Agent-First World, openai.com, 2026.02.11
- LangChain, The Anatomy of an Agent Harness, blog.langchain.com, 2026.03.10
产品案例
- Stripe Engineering, Minions: Stripe’s One-Shot, End-to-End Coding Agents, stripe.dev, 2026.02.09
- Anthropic, Effective Harnesses for Long-Running Agents, anthropic.com, 2025.11.26
研究数据
- Khan, Prompting Inversion, arXiv, 2025
- Laban et al., LLMs Get Lost In Multi-Turn Conversation, Microsoft + Salesforce, 2025
- Epsilla, Harness Engineering: Evolution from Prompt to Context to Autonomous Agents, 2026
我是 Jason,一个独立打造 AI 产品的创业者。如果这篇文章对你有启发,欢迎转发给关注 AI 工程的朋友。
我一个人打造的 Zaokit AI 产品(https://zaokit.app)正在内测,2026年5月31日前1000名用户赠送价值150RMB的Pro计划,助力大家高效完成图文创作和PPT生成,唯一网站:https://zaokit.app
最后,如果你认可 Zaokit AI 的产品理念,欢迎后台留言加入我们的社群。我们不卖课、不割韭菜,只聚焦 ToB 企业场景的 AI 落地实战。 希望在这里,能给你带来不一样的思维火花和真实的商业碰撞。
相关阅读: