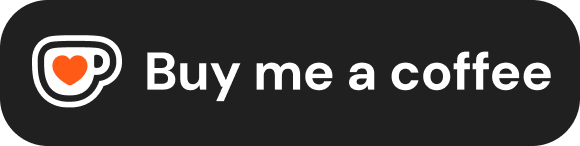2026年5月,华为董事、科学家委员会主任、半导体业务部总裁何庭波在学术预印本平台ChinaXiv上发表了一篇署名论文:《多层电子系统的时间缩放理论》。
这篇论文不长,但分量不轻。它用六年、381颗芯片的量产数据,白纸黑字写下了一件整个半导体行业心知肚明、却没人敢系统说透的事:摩尔定律的行业契约已经不再成立,后续该怎么走?
在回答”韬(τ)定律是什么”之前,我想先把两件事讲清楚:摩尔定律到底是什么,以及它为什么在今天失效了。

一、摩尔定律:半导体60年的”行业契约”
1965年,英特尔联合创始人戈登·摩尔(Gordon Moore)在一篇文章里写下了那个改变世界的观察:集成电路上的元器件数量大约每年翻一番。到了1975年,他把这个节奏修正为大约每两年翻一番。
这个规律背后还有更重要的推论,由罗伯特·丹纳德(Robert Dennard)在1974年补充完整:当晶体管等比例缩小时,电压也同步降低,功耗密度可以维持可控,性能和能效持续提升。
用最直白的话说:每过两年,同样大小的芯片上能塞的晶体管翻倍,价格更低、速度更快、能耗更省。
这不只是一个预测,更是一个行业契约——整个计算产业的商业模型都建立在这个契约上。从PC到手机,从搜索引擎到AI训练,过去60年的所有数字化红利,本质上都源于”晶体管越来越便宜”这个基础。
理解摩尔定律的关键:它从来不是关于”芯片变多厉害”,而是关于每颗晶体管的成本持续下降。半个世纪里,半导体产业用一句话总结:做小、做快、做便宜。
二、为什么摩尔定律在今天失效了?
问题在7nm之后集中爆发。
物理极限先到了。 晶体管已经小到几个原子的尺度,再往下缩会遇到量子效应——电子会”穿墙而过”(量子隧穿),晶体管无法正常关断。所谓Dennard缩放,其实早在2005年就已经失效,之后是靠FinFET、GAA等器件架构创新撑着。
经济极限紧随其后。 最先进的EUV光刻机一台造价约2亿美元,折旧成本直接推高晶圆成本;一颗2nm芯片的设计预算已超过10亿美元;更要命的是,最先进节点的每个晶体管成本曲线已经趋于平坦,有些情况下甚至在上升。
维持了五十年的契约——每一代以更低成本获得更多晶体管——已经不再成立。
对华为来说,这个问题更早、更直接地砸了过来:2020年后无法自由使用最先进制程能力,”买最新制程”的路径被完全封堵。这反而逼出了一个更根本的问题:如果不靠缩小晶体管,那靠什么让芯片性能继续提升?
何庭波在论文里给出了一个系统性的回答。
三、韬(τ)定律:换一个优化目标
论文的核心洞察是这样的:
摩尔定律从来就不是关于几何的。更小的晶体管让系统更快,是因为信号传递的距离更短、时间更短。空间缩放只是压缩时间的手段,不是目的本身。
既然如此,为什么不直接把时间作为度量单位?
这就是韬(τ)定律的核心:以时间常数τ为统一优化目标,从晶体管的皮秒级开关,到数据中心的秒级响应,跨越12个数量级,全链路对齐一个指标。制程节点成了众多优化手段之一,而非唯一手段。
形式上,τ是分层的:
| 层级 | τ代表什么 | 主要优化手段 |
|---|---|---|
| 晶体管层 | 开关延迟(皮秒级) | 材料、应变工程、GAA架构 |
| 电路层 | RC传播延迟(纳秒级) | 缩短连线、低κ介质、3D集成 |
| 芯片层 | 计算+存储访问(微秒级) | 架构设计、缓存层次 |
| 系统层 | 端到端消息传递(毫秒级) | 互联协议、拓扑结构 |
韬定律的本质:不再只盯着晶体管做小,而是让整个系统的"数据流动时间"持续缩短。当你换掉优化目标,原来被认为是劣势的东西,反而可能逼出一条新路。
四、韬定律的五个技术支柱
何庭波在论文中基于六年量产经验,给出了五个具体实现路径。
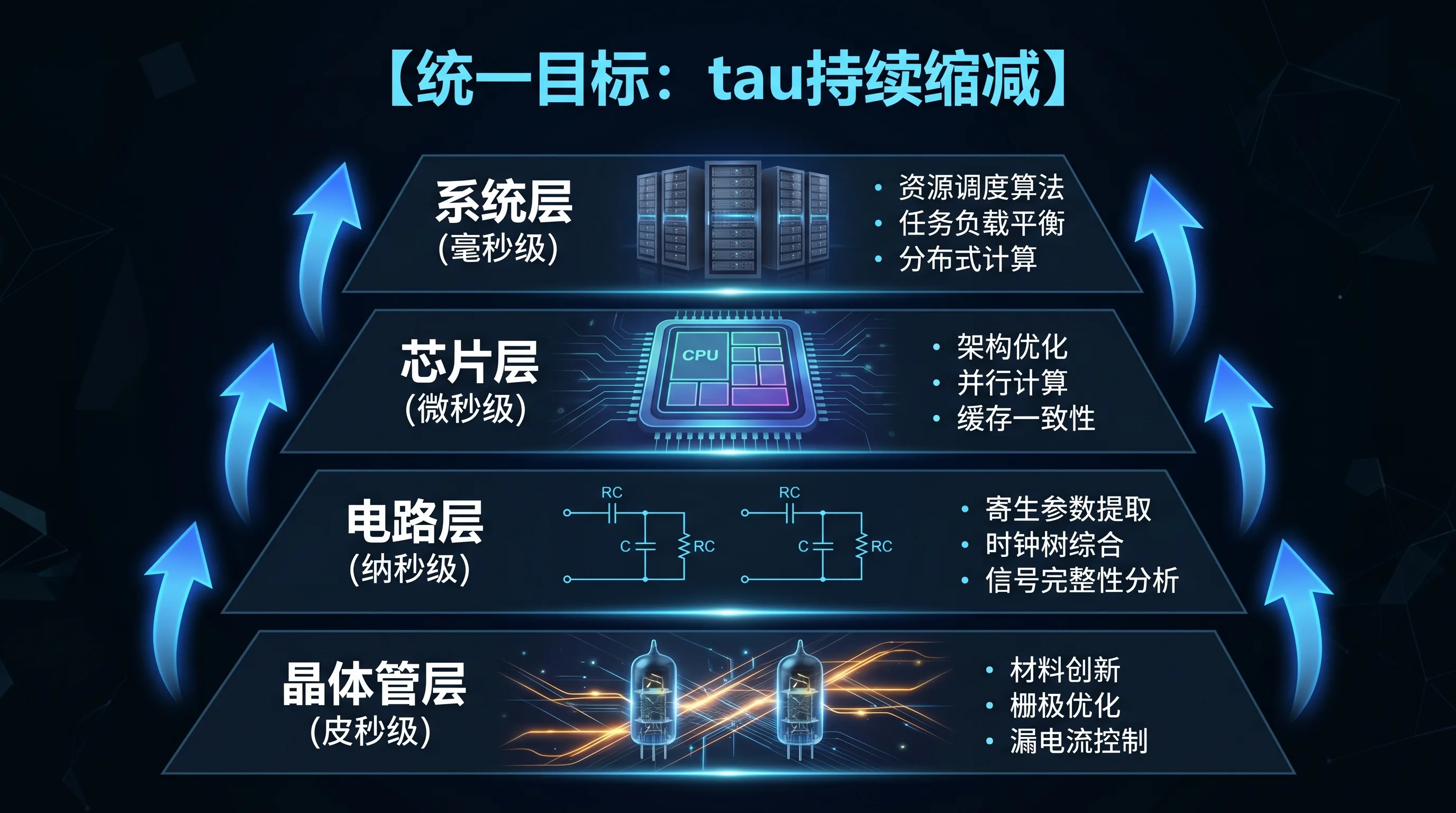
1. LogicFolding 逻辑折叠
传统芯片是”平铺”的——所有电路铺在一层硅片上,信号线在水平方向绕来绕去。线越长,寄生电容越大,信号越慢。
逻辑折叠做的事很直观:把原本水平铺开的电路,折到垂直方向。两层有源硅片通过超细间距混合键合连接,关键路径大幅缩短,等效于在不换制程节点的前提下,让芯片”变快”了。
按论文披露的数据:华为Kirin 2026在固定制程节点下,晶体管密度从155MTr/mm²跃升至238MTr/mm²(单代阶跃提升约54%,论文摘要称约55%),CPU能效提升41%,主频从2.75GHz提升至3.1GHz。需要注意,这些是华为论文披露的数据,不是第三方测评。不靠更先进制程,靠的是三维空间的重新排布。
2. Unified Bus 统一总线
传统AI集群的数据搬运需要穿越多层协议栈:PCIe→NVLink→以太网→RDMA→软件消息传递。每过一层就多一次协议转换、多一次延迟。
统一总线的思路是用一个协议替代所有协议,机箱内和机箱间都运行同一套内存语义,消除转换开销。
论文称,远程访问延迟可以从传统协议栈的几十微秒,降至约100纳秒——缩短约500倍。在机架规模上,整个集群对外看起来像一台机器,华为内部称之为”System-as-One-Chip / 系统即芯片”。
3. Hi-ONE 近封装光引擎
当单颗AI芯片带宽进入Tb/s级别,铜线就不够用了:太粗、太热、传不远。华为Hi-ONE是近封装光互连模块,单模块提供8Tb/s带宽,把SerDes传输距离从约100厘米缩到约5厘米,同时把面板间可达距离扩展到100米。
铜线管芯片内部,光纤管芯片之间。 这不是外挂的光模块,而是更接近”芯片原生光I/O”的集成方式。
4. 3D Folding 解决”边长困境”
传统2.5D封装有一个几何矛盾:逻辑芯片面积按N²增长,所以计算能力按面积增长;但HBM内存、SerDes、供电等资源只能沿封装边缘进入,带宽和电源按周长N增长。规模扩大后,算力越来越强,数据搬运的通道始终是瓶颈——这个问题不管制程多先进都无法解决。
3D Folding的解法:把原来”只能沿边缘进来”的资源(供电、内存、光I/O)转移到垂直方向,从周长扩展变成面积扩展,匹配计算能力的N²增长节奏。
5. 逻辑与内存的重新融合
过去几十年,CPU和内存是故意解耦的,各自独立演进。AI时代正在逆转这一趋势——AI训练对内存带宽的需求极高,数据搬移消耗的能量甚至超过计算本身。HBM、混合键合、3D堆叠SRAM都在说同一件事:把计算和存储尽可能靠近,减少数据”出门旅行”的距离和成本。
论文进一步判断:随着逻辑和内存融合,供应链的话语权会向内存和封装供应商倾斜。
五、为什么说三巨头的底层逻辑是一样的?
读完何庭波的论文,越来越觉得这不只是华为一家的故事。
华为、英伟达、台积电面对的是同一个根本问题:数据移动太慢、太贵、太耗电。 三条路线,同一个终点。

台积电的回答是先进封装。CoWoS侧重把逻辑芯片与HBM等放到中介层/基板上做2.5D整合,SoIC侧重把芯片在垂直方向堆叠,目的都是让原本需要长途跋涉的数据路径大幅缩短。台积电早就意识到先进制程太贵且良率存在物理瓶颈,所以大力发展”像搭积木一样拼芯片”的先进封装技术。
英伟达的回答是系统级整合。GB200 NVL72不是一颗GPU的故事,而是72颗Blackwell GPU通过NVLink连成一个域,72块GPU对外表现为一台统一的机器,内部提供130TB/s的GPU间通信带宽。英伟达现在卖的已经不是”芯片”,而是整套AI Factory——算力、内存、互连、软件栈一体化。
华为的回答是τ定律。在无法自由使用最先进制程的约束下,从全系统出发降低τ:LogicFolding缩短片内路径,统一总线消除协议转换开销,Hi-ONE推动近封装光I/O进入系统设计,3D Folding解决几何困境。
三条路线的差异也清晰:
- 台积电是制造/封装能力平台(”我能把你的设计做出来”)
- 英伟达是系统集成商(”我给你一整套算力基础设施”)
- 华为是体系化设计方法论(”我重新定义了什么是优化目标”)
但三者都在往”缩短数据路径”这个方向演进。这不是巧合,而是全球半导体产业对后摩尔时代的集体判断。
六、投资视角:后摩尔时代,钱追着什么走?
韬定律的逻辑如果成立,产业链上受益的就不只是晶圆厂,而是一整套围绕”缩短数据路径”的基础设施体系:
- 先进封装(CoWoS、SoIC):把芯片之间距离从厘米级压缩到微米级,台积电、长电科技等
- 光互连/硅光/CPO:机架之间的数据传输从铜线走向光纤,能耗和带宽双重改善
- 高带宽内存(HBM):存储离计算越来越近,HBM的战略价值不亚于GPU本身
- EDA工具链:传统EDA是二维时代的工具,3D原生、多物理场协同的EDA是未来十年的赋能基础
- 散热/液冷:集成度越高,热密度越高,散热反而成了新的卡脖子环节
- 系统软件/互联协议:硬件堆起来还不够,调度和通信协议也需要从头重构
从投资角度看,后摩尔时代的竞争维度从"晶体管做多小"变成了"数据走多短"。卡住这条链路上关键节点的公司,拥有和先进制程同等量级的战略价值,而且受益面更广、更分散、更难被单点垄断。
写在最后
摩尔定律死了,这不是悲剧,而是换了赛道。
何庭波这篇论文最值得借鉴的不是某个具体技术,而是换了一个优化目标:从”晶体管多小”变成”时间多短”。当你换掉目标函数,原来被认为是劣势的约束,反而可能逼出一条新路——这件事不只对华为有启发,对所有面临”旧路径走不通”的创业者和团队,都值得反复咀嚼。
不管是华为的τ定律、英伟达的AI Factory,还是台积电的先进封装,本质上都在回答同一个问题:在算力需求指数增长的时代,如何让数据以更低的成本流动?
这是一个还在展开的故事,而且未来十年会越来越有意思。
我是 Jason,一个独立打造 AI 产品的创业者。如果这篇文章对你有启发,欢迎转发给关注 AI 和半导体的朋友。
我一个人打造的 Zaokit AI 产品(https://zaokit.app)正在内测,2026年5月31日前1000名用户赠送价值150RMB的Pro计划,助力大家高效完成图文创作和PPT生成,唯一网站:https://zaokit.app
最后,如果你认可 Zaokit AI 的产品理念,欢迎后台留言加入我们的社群。我们不卖课、不割韭菜,只聚焦 ToB 企业场景的 AI 落地实战。 希望在这里,能给你带来不一样的思维火花和真实的商业碰撞。
相关阅读: