昨天下午,我开了两个半小时的需求评审会。
等我回到 Mac 前面,发现 Telegram 已经刷了一屏消息——不是群聊灌水,而是我的两只”虾”在汇报工作进度:Winnie 说 Voice Real-time Translation 的一个 bug 已修复并提了 PR;Amy 说微信公众号的文案初稿已生成,等我过目。
我泡了杯咖啡,花了 10 分钟 review 了 Winnie 的 PR,又花 5 分钟调了 Amy 的措辞,合并、发布,完事。
一句话结论:当你能用 3 个 Agent 跑通从任务派发到交付审核的完整闭环时,"一人团队"就不再是口号,而是每天在发生的事。

如果你只有 30 秒,先看这 3 句:
- 我用 OpenClaw 在本地 Mac 上搭了 3 个 Agent(编排器 + 编码助手 Winnie + 文案助手 Amy),它们能自主接收任务、执行工作、提交 PR、互相协作。
- 关键突破不是”Agent 能写代码”,而是监控脚本 + 自动重试 + Telegram 通知构成了一条零人工干预的闭环——我不在电脑前,它们也在干活。
- 月成本约 $190,相当于雇了一个 7×24 小时的两人小团队。但前提是:你得花时间”养”好这个生态。
一、从 Elvis 的”日均 50 次 Commit”说起
这件事的起点,是我在推特上读到了 Elvis(@elvissun)的一篇深度分享。
Elvis 不再直接使用 Codex 或 Claude Code 写代码,而是通过 OpenClaw 作为编排层,由 AI 助手统一调度多个编码 Agent。他管这套体系叫 Agent Swarm。他的公开数据让我坐不住了:
| 指标 | 数据 |
|---|---|
| 单日最高 commit | 94 次(平均每天约 50 次) |
| 30 分钟内完成 | 7 个 PR |
| 当天开客户会议 | 3 个(全程没打开编辑器) |
| 月成本 | Claude ~$100 + Codex ~$90 ≈ $190 |
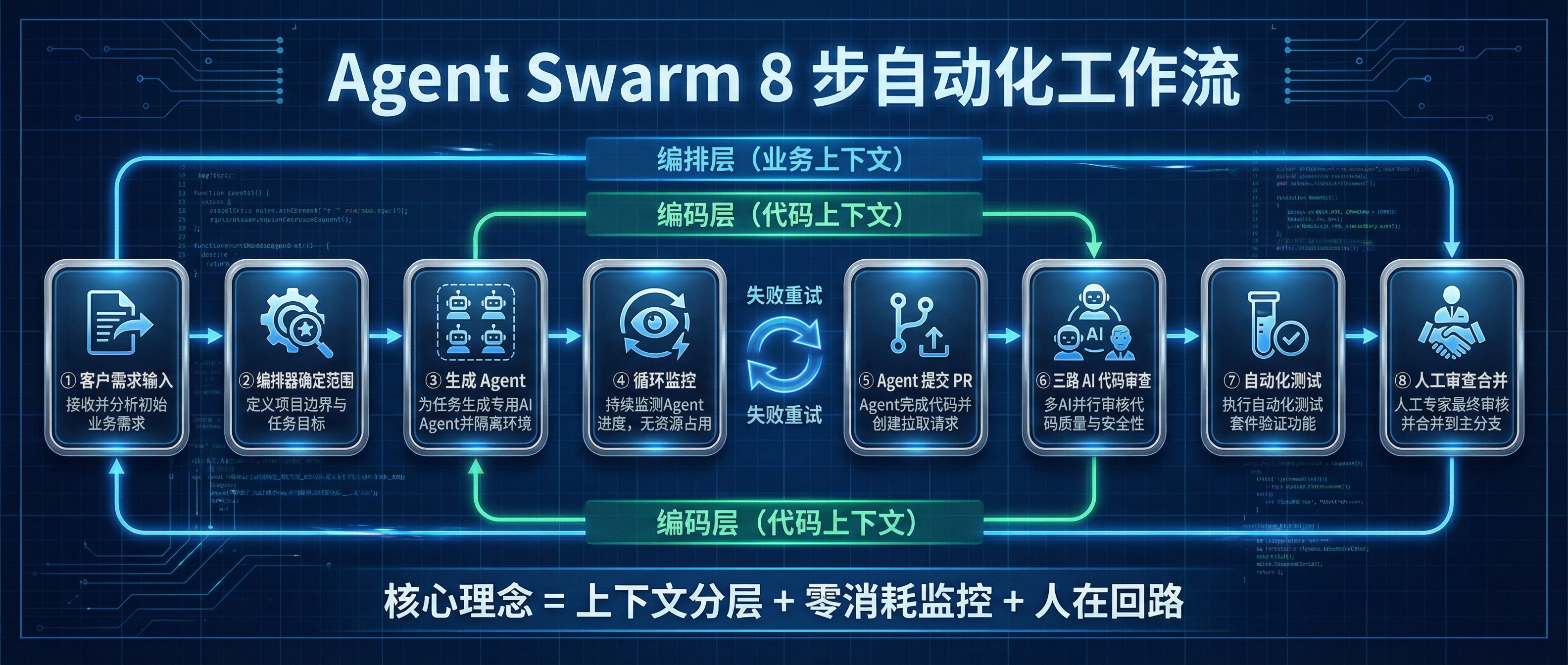
他的 8 步工作流覆盖了从客户需求到合并上线的完整周期:需求收集 → 编排器确定范围 → 生成 Agent(独立 worktree + tmux session) → cron 循环监控(零 token) → Agent 创建 PR → 三路 AI Code Review(Codex + Gemini + Claude) → 自动化测试 → 人工审查合并。
但真正让我决定动手的,是他提出的一个核心观点:
上下文窗口是零和的。填满代码,就没空间放业务上下文;填满客户历史,就没空间放代码。解决方案不是找更大的窗口,而是分层——编排层持有业务全局,编码层专注执行。
这和我之前在《开工第一天你必须看懂的 AI Coding 新秩序》里写的”Architect/Coder/QA 三角色协同”是同一个方向——只不过 Elvis 已经在生产环境跑通了。
二、我的 3 只虾:谁是谁,干什么
“养虾”这个比喻不是我发明的,但确实很贴切。
搭 Agent Swarm 的过程就像养虾:搭好虾塘(基础设施)、放虾苗(配置 Agent)、投饲料(派任务)、巡塘(监控脚本)、收虾(收 PR 和内容)。核心不在某一次操作的精彩,而是维护一个可持续运转的生态。
我目前的虾塘里有 3 只虾:
2.1 编排器(Main Orchestrator)——塘主
它是整个 Swarm 的中枢,负责接收我的意图、拆解任务、决定派给谁。
更关键的是,它能让 Agent 之间协作:比如 Winnie 做完一个新功能后,编排器可以自动让 Amy 写更新日志和发布文案——整条链路不需要我手动衔接。
2.2 Winnie(coding-assistant)——编码虾
它的人设是”先结论后步骤,优先可执行方案,不做大规模重构”。
| 配置项 | 详情 |
|---|---|
| AgentID | coding-assistant |
| 工作空间 | ~/.openclaw/agents/coding-assistant/workspace |
| 模型 | openai-codex/gpt-5.3-codex |
| 通知通道 | Telegram Bot: justjason5788 |
| 擅长 | 后端逻辑、全栈开发、重构、Bug 修复、测试 |
2.3 Amy(copywriting-assistant)——文案虾
它的人设是”输出可直接发布,擅长新媒体文案,A/B 两版,避免空话”。
| 配置项 | 详情 |
|---|---|
| AgentID | copywriting-assistant |
| 工作空间 | ~/.openclaw/agents/copywriting-assistant/workspace |
| 模型 | openai-codex/gpt-5.3-codex(fallback: claude-sonnet-4-5) |
| 通知通道 | Telegram Bot: jasonwenanbot |
| 擅长 | 中英双语、短视频/新媒体、SEO、小红书/微信/Twitter |
三者之间的分工逻辑很明确:
| 任务类型 | 指派 Agent | 原因 |
|---|---|---|
| Bug 修复 | Winnie | 代码理解 + 精准修复 |
| 新功能开发 | Winnie | 完整实现周期 |
| 代码重构 | Winnie | 跨文件变更能力强 |
| 博客文章 | Amy | SEO 优化 + 吸引力 |
| 社交媒体 | Amy | 平台原生风格 |
| API 文档 | Winnie | 技术准确性优先 |
| 用户指南 | Amy | 可读性优先 |
不是所有任务都适合自动化。关键是先把"可标准化派发"的任务跑通,再逐步扩展。
三、100% 自动化闭环:到底怎么跑通的
这是这篇文章的核心。我先画一张全景图,再逐步拆解每个环节。

3.1 派发:一条消息触发一个 Agent
派发有两种方式。
方式一:CLI 派发(适合批量或脚本触发)
# 派 Winnie 修 Bug
~/.openclaw/swarm/spawn-agent.sh winnie fix-auth-bug \
"Fix the login validation bug in auth.ts"
# 派 Amy 写文案
~/.openclaw/swarm/spawn-agent.sh amy blog-launch \
"写一篇产品发布博客,目标读者:开发者"
方式二:Telegram 消息派发(适合随时随地)
在 Telegram 里发消息给对应的 Bot,编排器自动路由。这也是我最常用的方式——开会间隙、地铁上、带孩子时,掏出手机发一条消息就行。
每次派发,系统内部会做 4 件事:
- 写入
active-tasks.json(任务注册表) - 创建独立 tmux session(互不干扰)
- 通过
openclaw agent --agent <id> --message '<prompt>' --local启动 Agent - 日志输出到
~/.openclaw/swarm/logs/<session>.log
3.2 执行:Agent 在 tmux 里自主工作
这是最关键的一步,也是”养虾”和”用工具”的本质区别。
Agent 启动后,在自己的 tmux session 里独立运行:
- 读取任务上下文和相关记忆
- 拉取代码到独立 worktree(不影响主分支)
- 自主编码或写作
- 自主运行测试
- 完成后自动
gh pr create --fill
整个过程不需要我盯屏幕。我可以去开会、做饭、带孩子——它们在后台持续工作。这就是从”操作工具”到”管理团队”的跃迁。
3.3 巡检:零 Token 的确定性监控
很多人会问:你怎么知道 Agent 干完了?干得对不对?卡住了怎么办?
答案是 check-agents.sh——一个 100% 确定性的 Shell 脚本,零 LLM token 消耗。
它的逻辑非常简单(也正因为简单,才稳定):
- 读取
active-tasks.json中所有活跃任务 - 逐一检查 tmux session 是否存活
- 通过
gh pr list检查 PR 和 CI 状态 - 自动标记失败任务,触发重试
- 超过 3 次重试则标记为 failed 并告警
- 只在需要人工介入时才发通知
配合 cron 每 10 分钟运行一次,这套巡检就像虾塘里的自动增氧机——你不需要 24 小时盯着,但它一直在工作。
3.4 状态机:从 running 到 review-ready
任务的状态流转是可追踪的:
running → done (成功完成)
running → blocked (需要人工输入)
running → ci-failed → respawning → running (自动重试)
running → session-dead → respawning (tmux 挂了,自动恢复)
running → failed (超过 3 次重试,人工介入)
done → review-ready (CI + review 全过)
整条链路里,唯一需要人的环节是最后 5-10 分钟的 review。其余全部自动化。这就是"100% 自动化闭环"的含义——不是"零人工",而是"人只做决策,不做执行"。
四、实战验证:Voice Real-time Translation 项目
光说架构没用,得拿真实项目验证。
我用这套 Swarm 实际参与管理的项目之一,就是之前文章里写过的 Voice Real-time Translation(macOS 应用名 VoiceTranslation)——一个专门解决 Teams 标准版”有字幕无翻译”痛点的 macOS 实时语音翻译器。
这个项目从 2025 年 8 月 11 日首次提交,到现在已经稳定运行半年,经历了两次关键重构(API Provider 管理重构 + 权限处理与音频质量监控重构)。在引入 Agent Swarm 后,工作方式发生了质变:
| 阶段 | 工作方式 | 典型效率 |
|---|---|---|
| 早期(2025.08-2025.12) | 我自己写代码,偶尔用 Claude 辅助 | 一个功能 2-3 天 |
| 重构后(2026.01-2026.02) | Winnie 写代码,我做 review | 一个功能 2-4 小时 |
| Swarm 接入后(2026.02.25 起) | 派发任务后去开会,回来 review | 并行处理 3-5 个任务 |
上周的一个真实案例:
我在开需求评审会,顺手在 Telegram 给 Winnie 发了一条消息:
“VoiceTranslation 的 Core Audio Tap 在蓝牙设备切换时偶尔丢帧,查一下 AudioStreamBasicDescription 的采样率同步逻辑,修复后跑 unit test。”
两个半小时后会议结束,Winnie 已经提了 PR,附带了修复代码和通过的测试用例。我 review 了 5 分钟,合并。
与此同时,Amy 在另一个 tmux session 里完成了一篇微信公众号文案的初稿。我调整了几处措辞,也发了。
一个下午,两个交付,人工介入总共 15 分钟。

五、虾塘的水电和增氧:技术架构全解
为了让不那么技术的读者也能理解,我用”虾塘”的比喻来对照每一层组件。
5.1 虾塘本体(基础设施)
| 组件 | 虾塘比喻 | 实际作用 |
|---|---|---|
| OpenClaw 2026.2.25 | 虾塘整体框架 | Agent 编排平台,统一调度所有 Agent |
| tmux sessions | 养殖池隔板 | 每个 Agent 独立运行空间,互不干扰 |
| git worktrees | 独立投喂区 | 每个 Agent 有自己的代码副本 |
| Telegram Bots | 对讲机 | 人与 Agent 的实时通信通道 |
| SQLite + Gemini Embedding | 虾的记忆 | 每个 Agent 独立记忆库,积累经验 |
5.2 饲料(模型配置)
| 模型 | 用途 | 选择理由 |
|---|---|---|
| openai-codex/gpt-5.3-codex | Winnie + Amy 主力 | Codex 在编码任务上的完成度最高 |
| anthropic/claude-sonnet-4-5 | Amy 的 fallback | 中文内容质量更优 |
| gemini-embedding-001 | 记忆系统向量搜索 | Embedding 质量与成本平衡 |
两个 Codex 账号轮换使用,避免单账号限额触顶:
"order": {
"openai-codex": [
"openai-codex:second",
"openai-codex:default",
"anthropic:manual"
]
}
5.3 增氧系统(监控工具链)
| 文件 | 作用 | 运行方式 |
|---|---|---|
active-tasks.json |
任务注册表,追踪所有 Agent 状态 | 实时更新 |
spawn-agent.sh |
一键派发脚本 | 按需调用 |
check-agents.sh |
零 token 巡检脚本 | cron 每 10 分钟 |
logs/ 目录 |
每个 session 的完整输出日志 | 持续写入 |
5.4 账号隔离策略
这是一个容易被忽略但极其重要的细节:
| 账号 | 用途 | 隔离原因 |
|---|---|---|
| k******[email protected] | 仅本地 macOS Codex CLI | 我的日常开发,不参与 Agent |
| j********[email protected] | OpenClaw Agent 主账号 | Agent session 独立消耗 |
| w********[email protected] | OpenClaw Agent 备用 | 限额轮换,避免触顶 |
为什么要隔离?因为 Agent 的 token 消耗量远超人类手动使用。如果共用一个账号,Agent 跑满限额后我自己就用不了了。
5.5 自建代理:成本控制的隐藏关键
我的 Anthropic 和 Gemini API 不是直接调用官方端点,而是通过自建代理访问(BaseURL: https://cc.junxinzhang.com)。好处是:统一管理所有 API 调用日志、实时监控成本、异常时可快速切换。
六、成本账:养虾到底花多少钱
6.1 参考数据:Elvis 的公开成本
| 项目 | 月费 |
|---|---|
| Claude API | ~$100 |
| Codex API | ~$90 |
| 合计 | ~$190/月 |
6.2 我的实际成本
我目前还在测试和调优阶段,任务密度没有 Elvis 那种”日均 50 commit”的级别。当前月成本大约 $50-80。
但核心不是”花多少钱”,而是产出比。一个初级开发者的月薪远不止 $190。而这两只虾 7×24 小时在线,没有社保、不请假、不需要管理。当然,它们不会主动提需求——这也是”人在回路”的价值所在。
6.3 硬件边界
| 配置 | 并发 Agent 上限 | 体验 |
|---|---|---|
| 16GB Mac | 4-5 个 | 够用,但接近上限时会卡 |
| 128GB Mac Studio M4 Max | 充分并发 | Elvis 推荐配置 |
瓶颈是 RAM,不是 CPU。每个 Agent 的 tmux session + worktree + 模型上下文都在吃内存。
七、踩过的坑(省你走弯路)
不说踩坑记录的文章是不完整的。以下是我搭建过程中最痛的几个:
7.1 网络代理干扰 Cloudflare Tunnel
问题:cloudflared 持续报错 “there are no free edge addresses left to resolve to”,QUIC timeout 不断。
根因:本地 Stash 代理(端口 7890)劫持了 DNS,将 Cloudflare edge 解析到假 IP 198.18.0.x。QUIC 使用 UDP,代理无法正确转发。
解法:在 Stash 配置中 bypass *.argotunnel.com;或者在 cloudflared 中添加 --protocol http2 强制 TCP。
教训:本地跑代理工具的同学特别注意——任何需要 UDP/QUIC 的服务都可能被代理干扰。
7.2 Codex Device Auth 在代理环境下失败
问题:执行 codex login --device-auth 始终无法完成认证流程。
解法:https_proxy="" codex login --device-auth,绕过代理即可。Business 工作空间还需管理员启用 device code auth。
7.3 Token 过期导致 Agent 静默失败
问题:Codex OAuth token 有效期约 10 天。过期后 Agent 不报错,只是静默停止工作——这是最阴险的 bug,因为你以为虾还在干活,其实已经罢工了。
解法:在 check-agents.sh 中增加 token 有效性检查。定期刷新 token 并同步到 OpenClaw。备份机制:~/.codex/auth.json.kiyo.bak。
7.4 新旧版本共存导致 CLI 冲突
问题:本地同时存在 ~/.clawdbot/(旧版 Clawdbot 2026.1.24-3)和 ~/.openclaw/(新版 OpenClaw 2026.2.25),两套 CLI、两套 Memory DB、两个 Gateway 端口,互相干扰。
解法:统一以 ~/.openclaw/ 为准,旧版不再使用。切记清理干净,否则后台进程可能占端口。
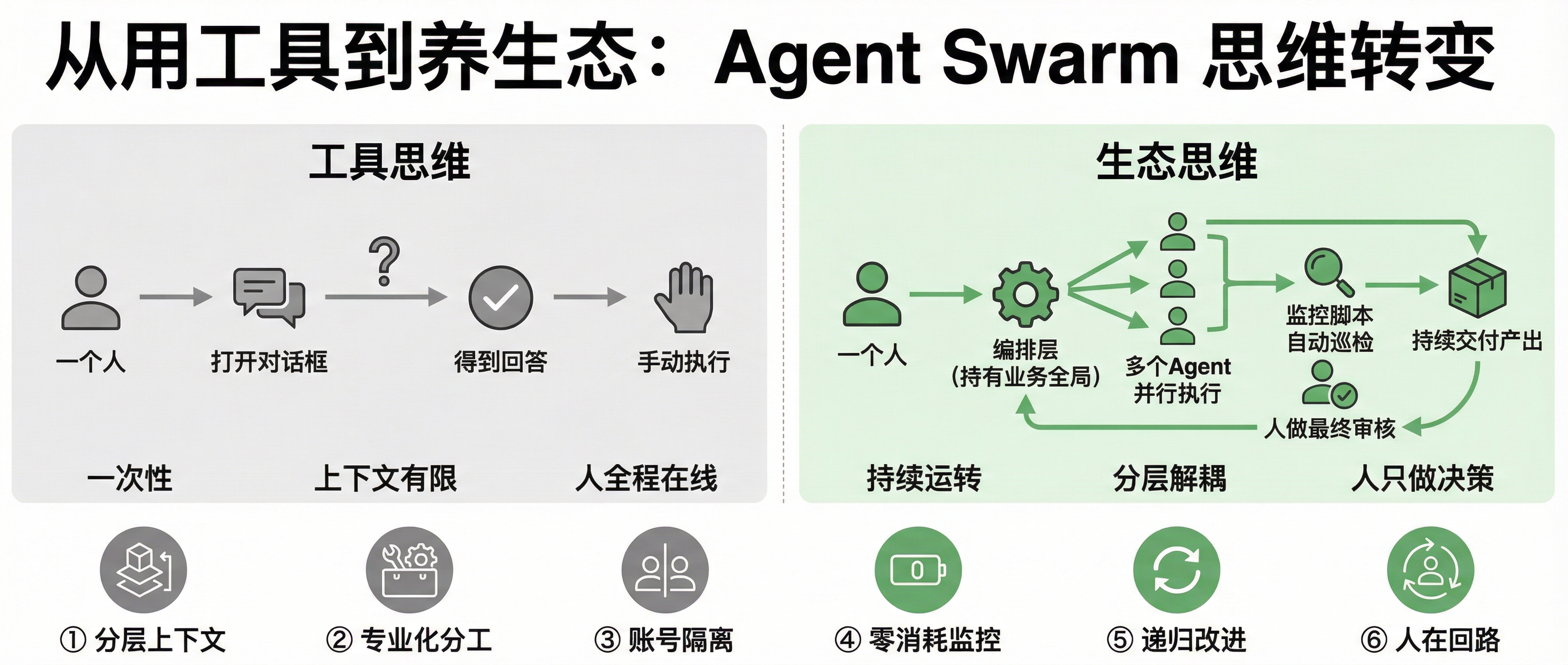
八、从”用工具”到”养生态”:6 条核心理念
总结这段实践,我提炼了 6 条核心原则:
- 分层上下文:编排器持有业务全局,Agent 专注执行。不要让一个 Agent 又懂业务又写代码——这会快速吃光上下文窗口。
- 专业化分工:Winnie 写代码,Amy 写文案,各司其职。混用一个通用 Agent 做所有事的效果远不如专业化配置。
- 账号隔离:我本地开发用一个账号,Agent 跑任务用另外的账号,互不干扰、互不抢限额。
- 零 Token 监控:确定性脚本巡检,只在需要时消耗 API。监控本身不应该是 LLM 任务——这是很多人容易犯的错。
- 递归改进:成功的 prompt 模式记入 memory,失败的也记录原因和修复方案。每一次执行都在为下一次积累经验。
- 人在回路:Agent 做 80% 的执行工作,人做 20% 的决策和审查。完全无人介入不是目标,高效协作才是。
写在最后
“养虾”不是一个精确的技术词,但它抓住了一个本质:
AI Agent 的价值不在单次调用的惊艳,而在持续运转的生态。
搭好虾塘、选好虾苗、配好饲料、装好增氧机——然后你可以去做更重要的事:思考业务方向、和客户对齐需求、做技术决策。那些能被标准化拆解和重复执行的工作,交给虾去做。
我目前的 Swarm 还在早期阶段,接下来会继续推进几件事:
- 配置 cron 定时运行 check-agents.sh
- 测试 Winnie → Amy 的跨 Agent 自动协作链路
- 引入三路 AI Code Review(Codex + Gemini + Claude)
- 扩展更多 Agent 角色:SEO 专家、数据分析
- 持续积累 memory,让每只虾越养越聪明
如果你也在琢磨 Agent Swarm,或者对 OpenClaw 有实操经验,欢迎交流。
一个人 + AI Agent Swarm = 一个团队。这不再是愿景,而是每天在发生的事。
相关阅读
OpenClaw 系列
- 用 OpenClaw 做 A 股量化?我试了试,聊聊真实感受
- Mac Mini 被 AI 圈抢光了,真的值得买吗?我的 OpenClaw 实测体验
- OpenClaw 尝鲜报告:这款爆火的 AI 工具,现在能用吗?
AI 工程系列
- Teams 只有字幕没有翻译?我在 macOS 做了一个实时语音翻译器
- 从 GLM-5、MiniMax 到”红包大战”:开工第一天你必须看懂的 AI Coding 新秩序
- AI 订阅收紧潮:从 Anthropic 到 Google、GLM,免费午餐真的结束了
参考资料(官网/官方)
- OpenClaw 官方文档 https://docs.openclaw.ai/
- Elvis(@elvissun):Agent Swarm 方法论原文 https://x.com/elvissun/article/2025920521871716562
- OpenAI Codex 官方文档 https://openai.com/codex
- Anthropic Claude API 文档 https://docs.anthropic.com/
- Google Gemini Embedding API https://ai.google.dev/gemini-api/docs/embeddings
- Apple WWDC24 - Core Audio Taps(VoiceTranslation 项目参考) https://developer.apple.com/videos/play/wwdc2024/10153/